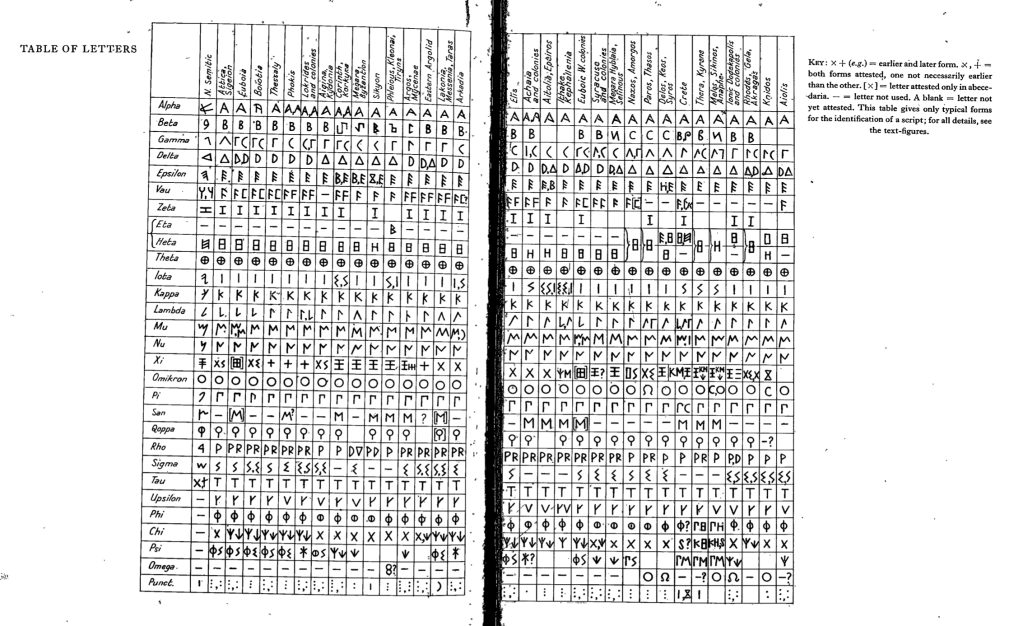
Complexity trends for three letters over 700 years on Euboea,
from my forthcoming diachronic study.
When I began APEX seven months ago, I wrote that before theory comes tracing—the act of turning old strokes into structured data. Half a year later, that small act has grown into something larger: a functioning, extensible research environment capable of analyzing thousands of letterforms across hundreds of inscriptions.
If the last few months have been about proving the analytical potential of APEX, this one has been about deepening its usability—turning it from a powerful engine into a genuine workspace. The latest version, 1.9.1, focuses on the graphical user interface, which I only dreamed of last April. The idea was to give form to the human side of paleographemics: how scholars see, record, and reason through inscriptions.
The platform now balances two goals that usually pull in opposite directions. It is rigorous enough to handle multilingual, multi-directional corpora across millennia, yet flexible enough to capture interpretive uncertainty and scholarly disagreement.
1. The Corpus Grows
APEX now contains its first completed regional corpus: 209 lead curse tablets from 5th-century BCE Styra (Euboea), encompassing 1,857 individual glyphs, each manually traced, annotated, and analyzed through the full APEX pipeline. Alongside this is a parallel dataset of another 99 Euboean inscriptions, spanning roughly eight centuries—from the Archaic through the Hellenistic period—processed through an exploratory workflow still in development.
Together, these two datasets represent 4,990 glyphs from the island of Euboea alone, making this one of the largest and most detailed regional paleographic corpora currently in existence. This body of material allows APEX not only to test technical scalability but to examine a single region’s graphical traditions across a complete chronological arc.
Within Styra alone, clear structural tendencies emerge. Across the 1,857 analyzed glyphs, symmetry and complexity show a strong inverse relationship, as expected, but now quantified. Others—especially theta and, unexpectedly, many iotas—deviate, showing that simplicity and circularity were not universal ideals but locally negotiated habits.
Across the broader eight-century span, early tendencies toward angularity give way to smoother, more balanced forms. Though not universally—delta stands out, evolving from a 2-stroke rounded D-shape to the familiar 3-stroke angular Δ, a shift that mirrors the broader transition from ductus-driven to design-driven writing. Nonetheless, this broadly confirmed long-standing epigraphic intuitions, but for the first time, making them concrete and measurable.
Taken together, the data suggest that what epigraphers once described qualitatively as a “balanced hand” or “tidy style” can now be measured as a structural principle—evidence that writers (whoever they may be, trained scribes or so-called ordinary people) in 5th-century Styra pursued an underlying visual economy that blurred the boundary between mechanical habit and aesthetic intention.
2. The Interface Takes Shape
v1.9.1 particularly hinges on a comprehensive Inscription Metadata panel—a modular framework for recording everything an inscription can tell us: provenance, language, writing direction, translation, confidence, and context.
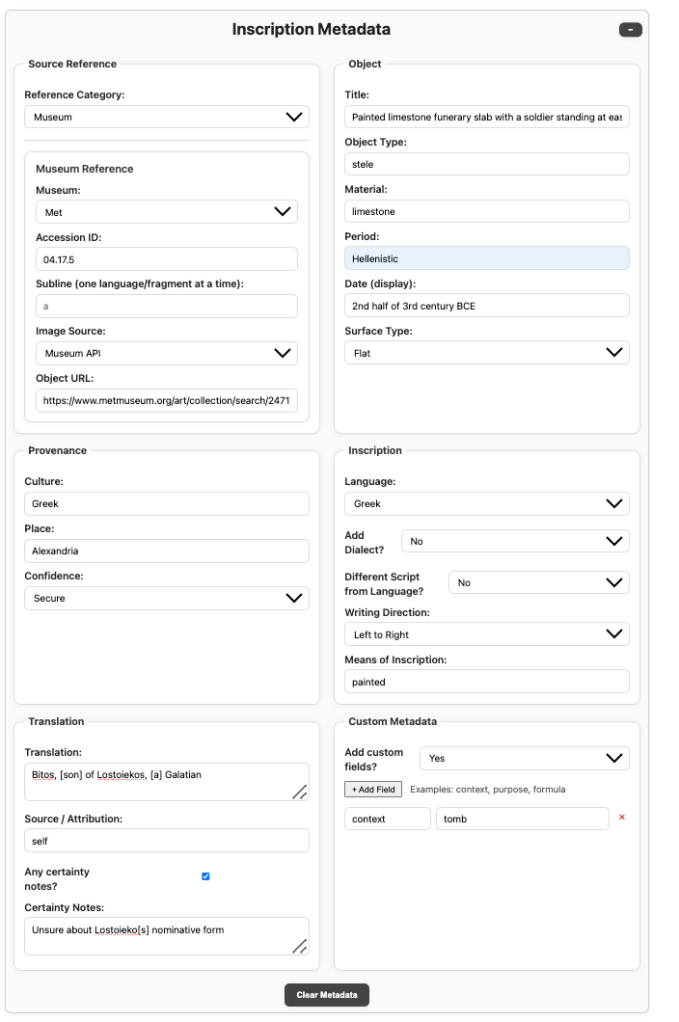
allow highly dimensional, unsupervised machine learning (ML) to be performed.
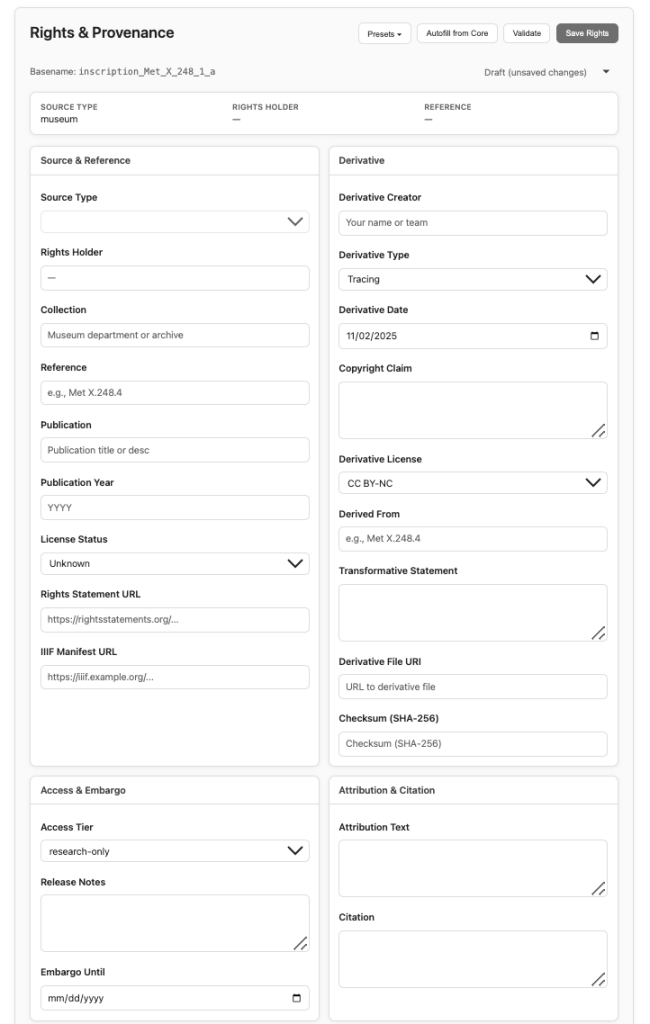
Furthermore, there’s an extensive rights and permissions panel just below that. This enables future rights-safe integration with public databases, preserving sensitive and restricted information from accidental reproduction—critical in heritage preservation and in preventing looting/destruction, especially in conflict zones. Now that I’m pivoting to working with data outside of the public domain, this is a non-negotiable feature, and I hope this is a practice that others replicate when fusing rights-diverse corpora. Below is the model of that.
Each record can now be broken into sublines, allowing users to specify separate languages and writing directions within a single inscription. This makes it possible to manually encode boustrophedon layouts, alternating left-to-right and right-to-left lines without losing reading order. The same applies for multilingual inscriptions: the user isolates each portion of a different language subline to analyze individually. However, true schlangenschrift—the serpentine style of continuous directional change—remains a technical frontier still ahead, but the architecture for handling it is now in place.
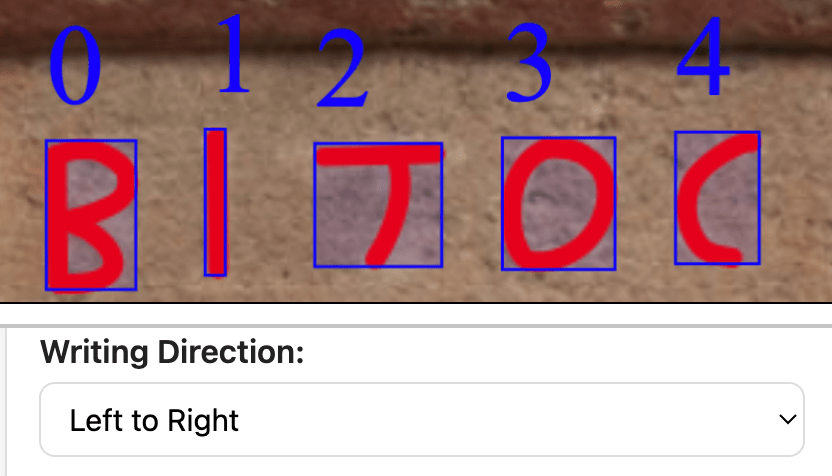

Bounding boxes are direction-aware, indexed according to reading orientation, ensuring that extracted visual features align correctly with the direction of writing. Metadata imports from museum APIs are now supported, and flexible fields allow users to enter additional descriptors such as inscription purpose, formula, or archaeological context.
3. Encoding the Human Element
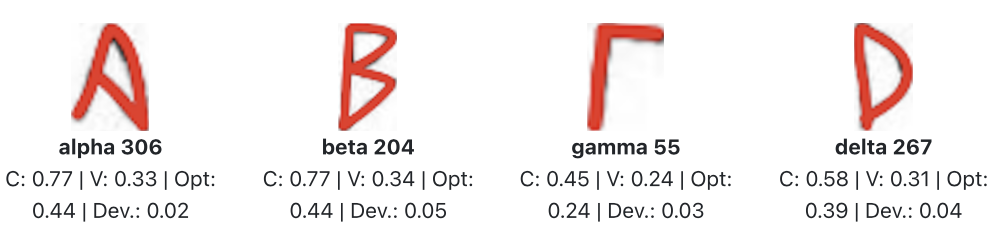
Each glyph now carries its own metadata through a compact per-glyph panel. Users can record completeness, stroke count, and intersection data, and—critically—can flag alternative readings where forms are contested. The new Scholarship Mode attributes alternate identifications to specific scholars or corpora, creating a visible interpretive genealogy and turning disagreement into structured data.
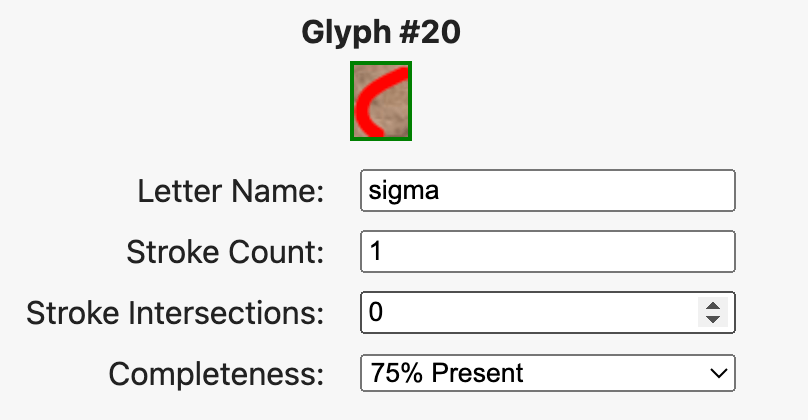
What results is a layered model of knowledge. APEX no longer treats the epigrapher’s uncertainty as noise; it considers it data. Each recorded disagreement becomes part of the historical record of how these inscriptions have been read.

4. Intelligent Defaults
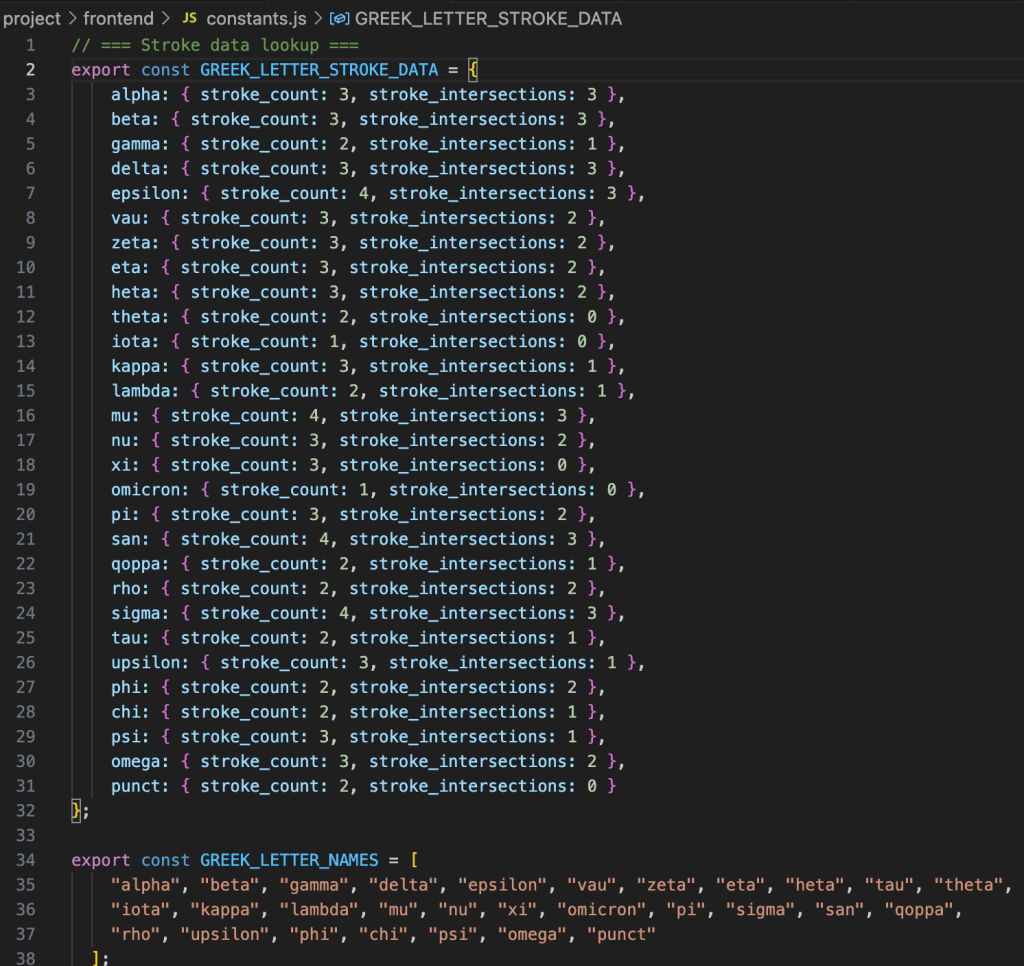
Five editable, language-aware dictionaries now exist for the GCELL script cluster, i.e., Greek, Coptic, Etruscan, Latin, and Lydian. There are another five dictionaries on the way for the PASHA branch: Phoenician, Aramaic, Semitic, Hebrew, and Arabian. This capability autofills letter names with their expected stroke and intersection counts, cutting per-glyph processing time by ~70%. These default expectations provide baselines for feature extraction and make visible the subtle divergences that define local or experimental hands.
5. From Interface to Insight
The combination of robust metadata, per-glyph fields, and structured dictionaries has turned APEX into a living research environment. A researcher can now import an object from a museum API, record multilingual metadata, define directionality, tag individual glyphs, and export a ready-to-analyze JSON file—all within a single interface.
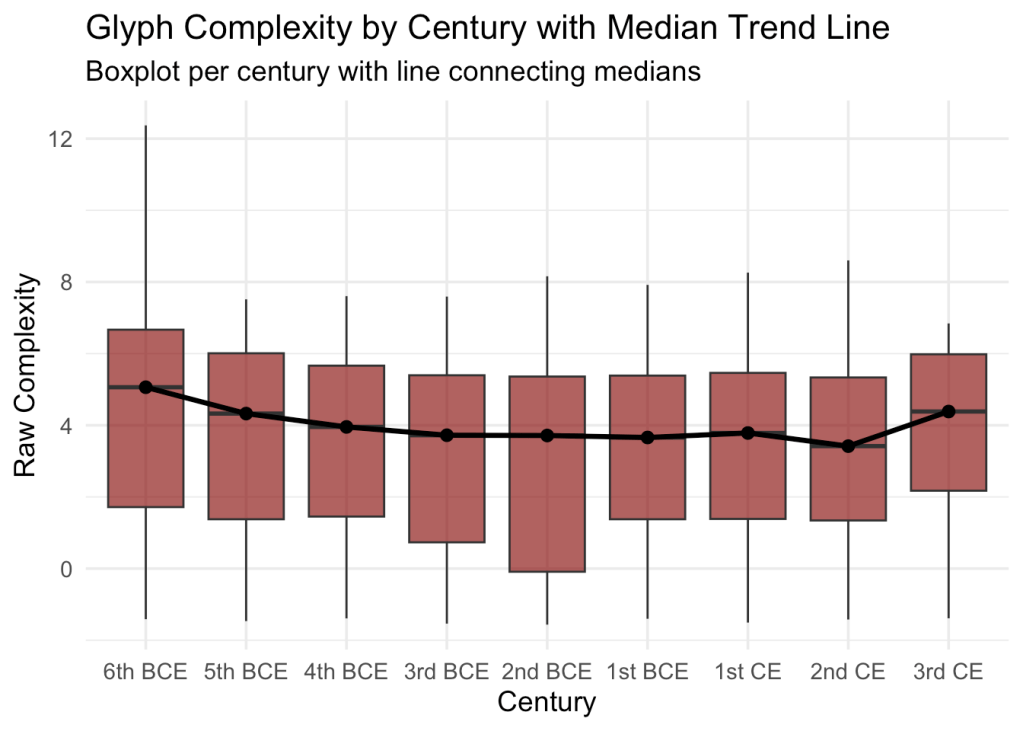
Early exploratory notebooks using the full eight-century dataset are already visualizing regional drift and stylistic convergence over time. Though not yet publishable, these models provide a first view of how letterforms move within and between centuries, forming clusters of continuity and outliers of innovation.
Critically, they also provide examples contrary to certain received wisdom. See the following chart, and note that the p-value of this correlation is p = 0.37, well above the <0.05 threshold for statistical significance in the social sciences.
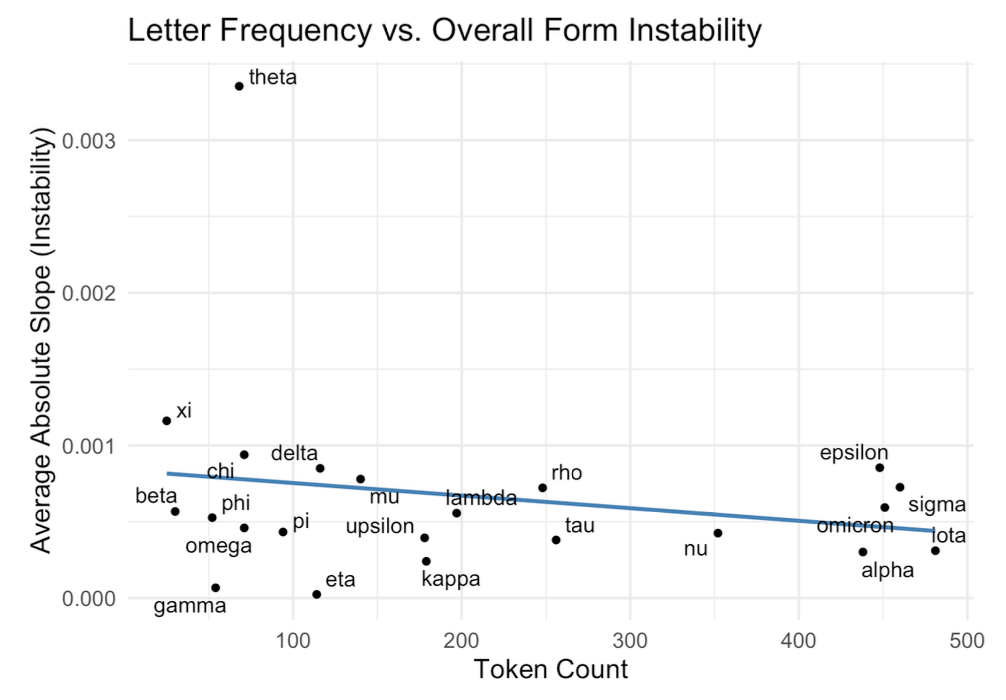
In the eight-century dataset, letter frequency shows only a weak and statistically insignificant relationship to graphical stability. The trend line slopes slightly downward—more common letters like alpha, sigma, and omicron are somewhat more stable—but the effect is far from reliable. This suggests that the conventional linguistic expectation—that frequently used units remain more conservative—does not translate cleanly to letterforms. Here, stability may follow style and medium more than frequency.
6. Reflection
The major achievement of this phase is not simply scale—it’s integration. APEX has reached a point where drawing, data entry, and interpretation form a continuous loop. Each inscription is both a record of ancient writing and a record of modern reading.
With nearly five thousand glyphs from one major region already processed, APEX is beginning to reveal what paleographemics promises: the ability to study writing as a cultural system that can be seen, measured, and compared without losing its human texture.
Download a PDF of the abridged report (13 pages): A Synchronic Analysis of 5th-Century BCE Lead Tablet Inscriptions from Styra on Euboea