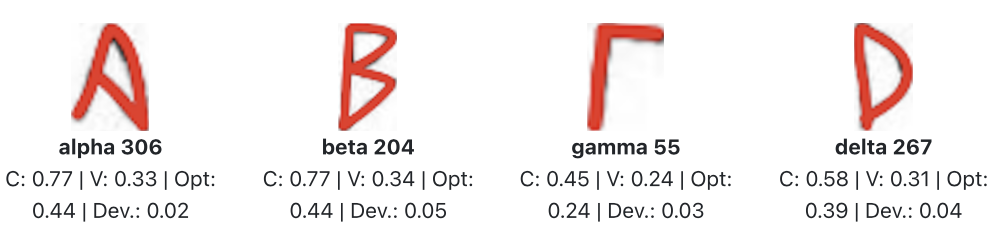
Clarice from Calvino’s Invisible Cities, as drawn by Karina Puente.
In the last decade the digital humanities have built an ethics of stewardship around two frameworks: FAIR and CARE.
Data, we’re told, should be Findable, Accessible, Interoperable, Reusable; its use should uphold Collective benefit, Authority to control, Responsibility, and Ethics. These principles have given structure to a once-couture, even cowboy, practice. They taught us that visibility is a virtue, that openness can be an act of justice. They made data management legible—something one could rate, certify, or defend.
Yet legibility is never neutral. FAIR presumes that clarity is the highest good; CARE assumes that control can be cleanly assigned. Both, however gently, rest on the dream of completeness: that if we organize our data well enough, we might finally see the whole.
APEX lives where that dream dies. The inscriptions I trace resist closure. They are fragmentary, re-inscribed, half-lost. Every dataset carries the tremor of its source—a chipped delta, a missing ‘alep, a surface that refuses to yield. The data, like the stones themselves, is frail.
I’ve begun to imagine a third paradigm: one that keeps FAIR’s discipline and CARE’s ethics but admits that in the humanities, stability is fictional. Call it FRAIL: Findable, Reproducible, Accountable, Interpretive, and Liminal.
Findable—disappearance helps no one.
Reproducible—others should be able to retrace our steps, even if they find another path.
Accountable—provenance and responsibility cannot be dispensed of.
Interpretive—ambiguity, when recorded, becomes part of the evidence itself.
Liminal—some knowledge dwells on thresholds: certainty and speculation, artifact and idea.
FRAIL doesn’t replace FAIR or CARE but grows from them. It asks what stewardship looks like when the object of study is itself uncertain, when our task is to hold the fragment without pretending it is whole.
At this point I keep returning to Calvino’s Invisible Cities. In “Cities and Names 4,” he writes of Clarice, a city that forever rebuilds itself from the shards of its earlier selves:
“Only this is know for sure: a given number of objects is shifted within a given space, at times submerged by a quantity of new objects, at times worn out and not replaced; the rule is to shuffle them each time, then try to assemble them. Perhaps Clarice has always been only a confusion of chipped gimcracks, ill-assorted, obsolete.”
Clarice is every archive we have ever built. Its fragments persist, rearranged with each generation, their order provisional, their meaning renewed by use. FRAIL data lives in that same condition: never whole, yet never lost—structures of care built from what survives. The humanities have always been a discipline of rebuilding Clarice.
To keep data FRAIL is therefore not to weaken it but to recognize its true strength: the capacity to bear transformation without disowning its past. Rigor becomes a form of tenderness. Reproducibility includes hesitation. The dataset, like the inscription, becomes layered, self-aware, and open to rereading.
In APEX I try to move toward that kind of data: technically precise yet narratively honest, transparent about its mediation, willing to show its seams. The goal isn’t immortality but traceability—to make each decision legible without pretending it ends the story.
Perhaps that is what stewardship finally means: not to eliminate fragility, but to hold it safely, as one holds a fragment of Clarice—knowing it has already been broken, and still believing it can be assembled again.
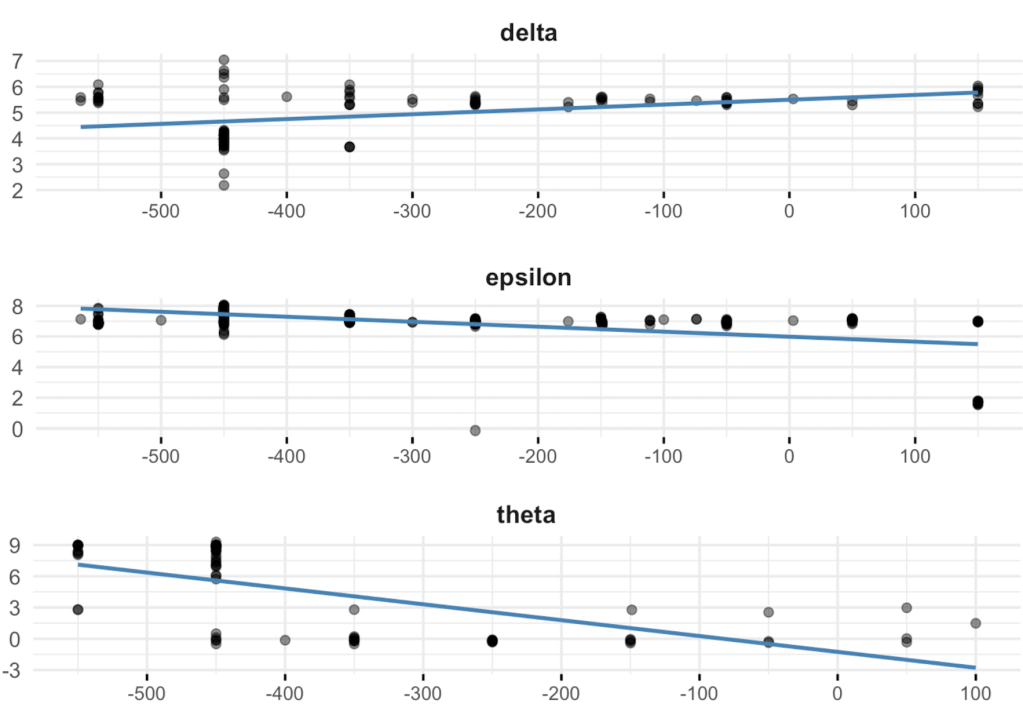
Complexity trends for three letters over 700 years on Euboea, from my forthcoming diachronic study.
When I began APEX seven months ago, I wrote that before theory comes tracing—the act of turning old strokes into structured data. Half a year later, that small act has grown into something larger: a functioning, extensible research environment capable of analyzing thousands of letterforms across hundreds of inscriptions.
If the last few months have been about proving the analytical potential of APEX, this one has been about deepening its usability—turning it from a powerful engine into a genuine workspace. The latest version, 1.9.1, focuses on the graphical user interface, which I only dreamed of last April. The idea was to give form to the human side of paleographemics: how scholars see, record, and reason through inscriptions.
The platform now balances two goals that usually pull in opposite directions. It is rigorous enough to handle multilingual, multi-directional corpora across millennia, yet flexible enough to capture interpretive uncertainty and scholarly disagreement.
1. The Corpus Grows
APEX now contains its first completed regional corpus: 209 lead curse tablets from 5th-century BCE Styra (Euboea), encompassing 1,857 individual glyphs, each manually traced, annotated, and analyzed through the full APEX pipeline. Alongside this is a parallel dataset of another 99 Euboean inscriptions, spanning roughly eight centuries—from the Archaic through the Hellenistic period—processed through an exploratory workflow still in development.
Together, these two datasets represent 4,990 glyphs from the island of Euboea alone, making this one of the largest and most detailed regional paleographic corpora currently in existence. This body of material allows APEX not only to test technical scalability but to examine a single region’s graphical traditions across a complete chronological arc.
Selected gallery of “Most Typical Glyphs by Letter” from Styra lead tablet report.
Within Styra alone, clear structural tendencies emerge. Across the 1,857 analyzed glyphs, symmetry and complexity show a strong inverse relationship, as expected, but now quantified. Others—especially theta and, unexpectedly, many iotas—deviate, showing that simplicity and circularity were not universal ideals but locally negotiated habits.
Classical intuitions—decreasing complexity through the Archaic and Early Classical periods, a plateau, then a late stylistic uptick—are confirmed here, but more importantly, they’re now quantified
Across the broader eight-century span, early tendencies toward angularity give way to smoother, more balanced forms. Though not universally—delta stands out, evolving from a 2-stroke rounded D-shape to the familiar 3-stroke angular Δ, a shift that mirrors the broader transition from ductus-driven to design-driven writing. Nonetheless, this broadly confirmed long-standing epigraphic intuitions, but for the first time, making them concrete and measurable.
Taken together, the data suggest that what epigraphers once described qualitatively as a “balanced hand” or “tidy style” can now be measured as a structural principle—evidence that writers (whoever they may be, trained scribes or so-called ordinary people) in 5th-century Styra pursued an underlying visual economy that blurred the boundary between mechanical habit and aesthetic intention.
2. The Interface Takes Shape
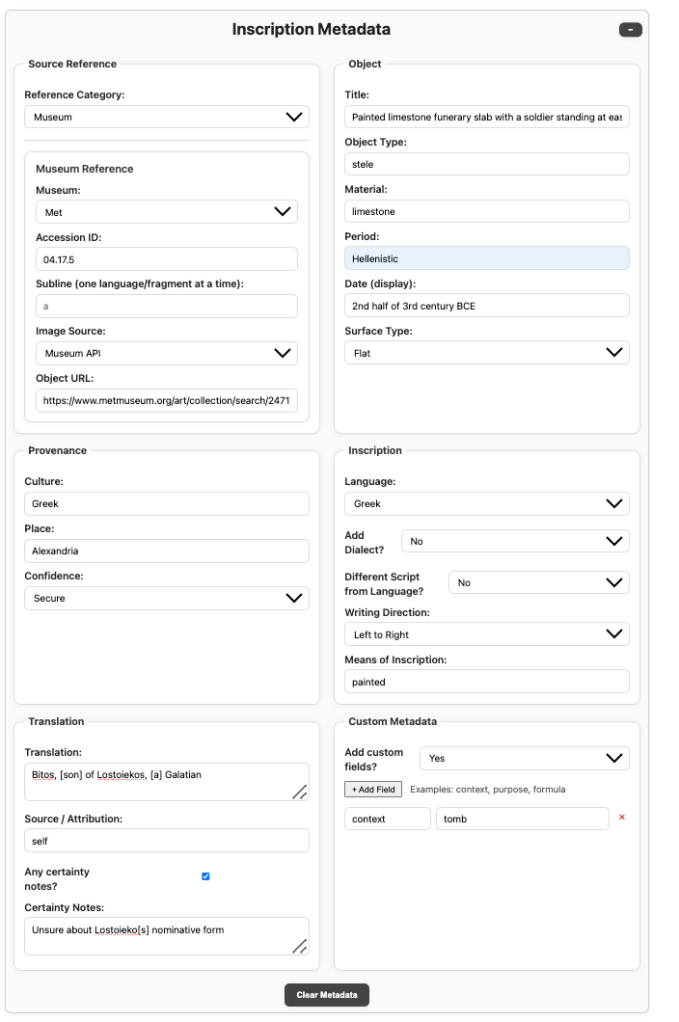
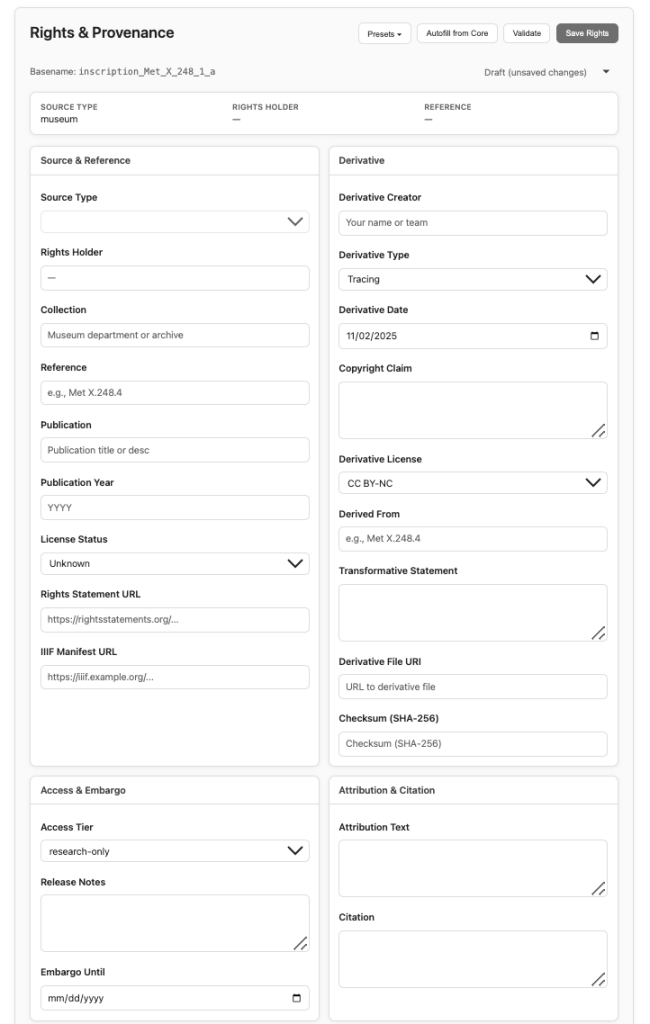
v1.9.1 particularly hinges on a comprehensive Inscription Metadata panel—a modular framework for recording everything an inscription can tell us: provenance, language, writing direction, translation, confidence, and context.
The (very granular) metadata panel, designed for maximum precision. This will later allow highly dimensional, unsupervised machine learning (ML) to be performed.
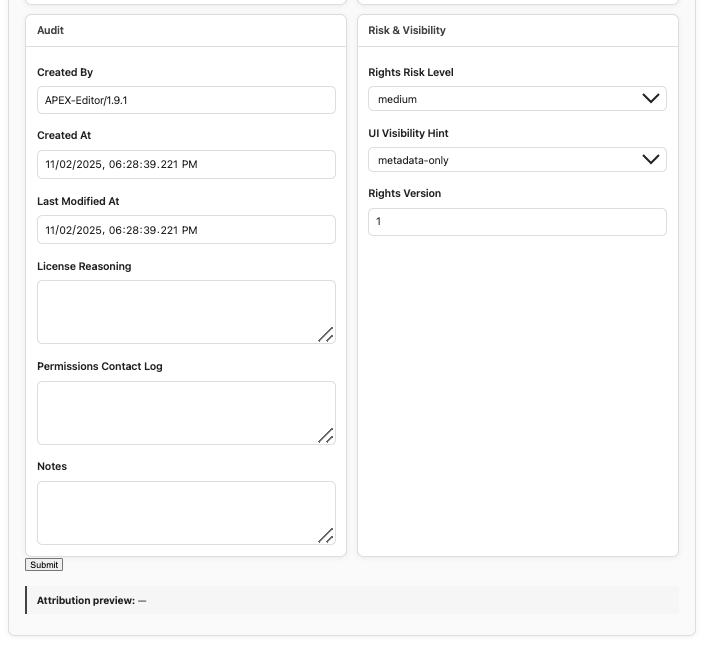
Furthermore, there’s an extensive rights and permissions panel just below that. This enables future rights-safe integration with public databases, preserving sensitive and restricted information from accidental reproduction—critical in heritage preservation and in preventing looting/destruction, especially in conflict zones. Now that I’m pivoting to working with data outside of the public domain, this is a non-negotiable feature, and I hope this is a practice that others replicate when fusing rights-diverse corpora. Below is the model of that.
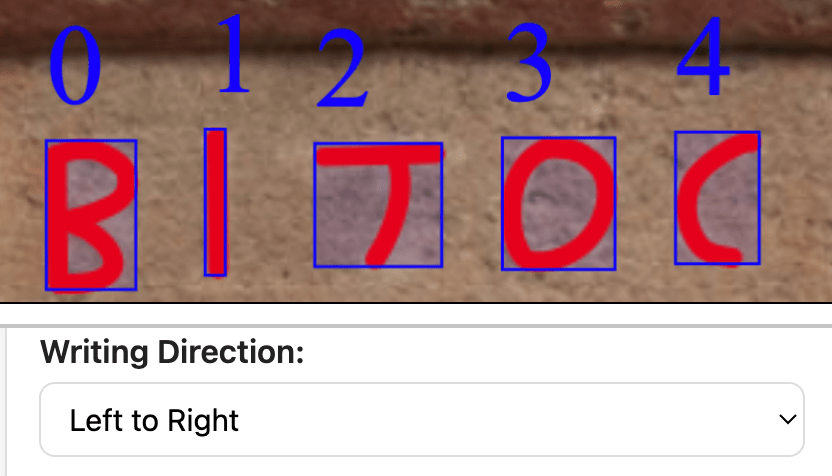
Each record can now be broken into sublines, allowing users to specify separate languages and writing directions within a single inscription. This makes it possible to manually encode boustrophedon layouts, alternating left-to-right and right-to-left lines without losing reading order. The same applies for multilingual inscriptions: the user isolates each portion of a different language subline to analyze individually. However, true schlangenschrift—the serpentine style of continuous directional change—remains a technical frontier still ahead, but the architecture for handling it is now in place.
For a Greek inscripion.For an Aramaic inscription.
Bounding boxes are direction-aware, indexed according to reading orientation, ensuring that extracted visual features align correctly with the direction of writing. Metadata imports from museum APIs are now supported, and flexible fields allow users to enter additional descriptors such as inscription purpose, formula, or archaeological context.
3. Encoding the Human Element
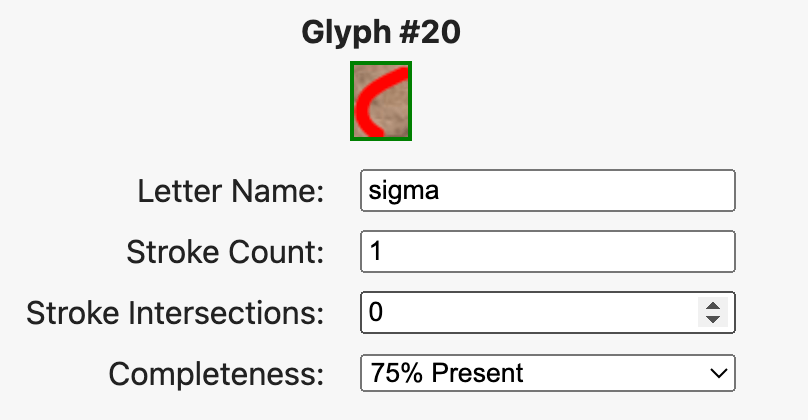
Each glyph now carries its own metadata through a compact per-glyph panel. Users can record completeness, stroke count, and intersection data, and—critically—can flag alternative readings where forms are contested. The new Scholarship Mode attributes alternate identifications to specific scholars or corpora, creating a visible interpretive genealogy and turning disagreement into structured data.
5-tier completeness flags now present.
What results is a layered model of knowledge. APEX no longer treats the epigrapher’s uncertainty as noise; it considers it data. Each recorded disagreement becomes part of the historical record of how these inscriptions have been read.
User can now cite alternative readings and the reasoning for them.
4. Intelligent Defaults
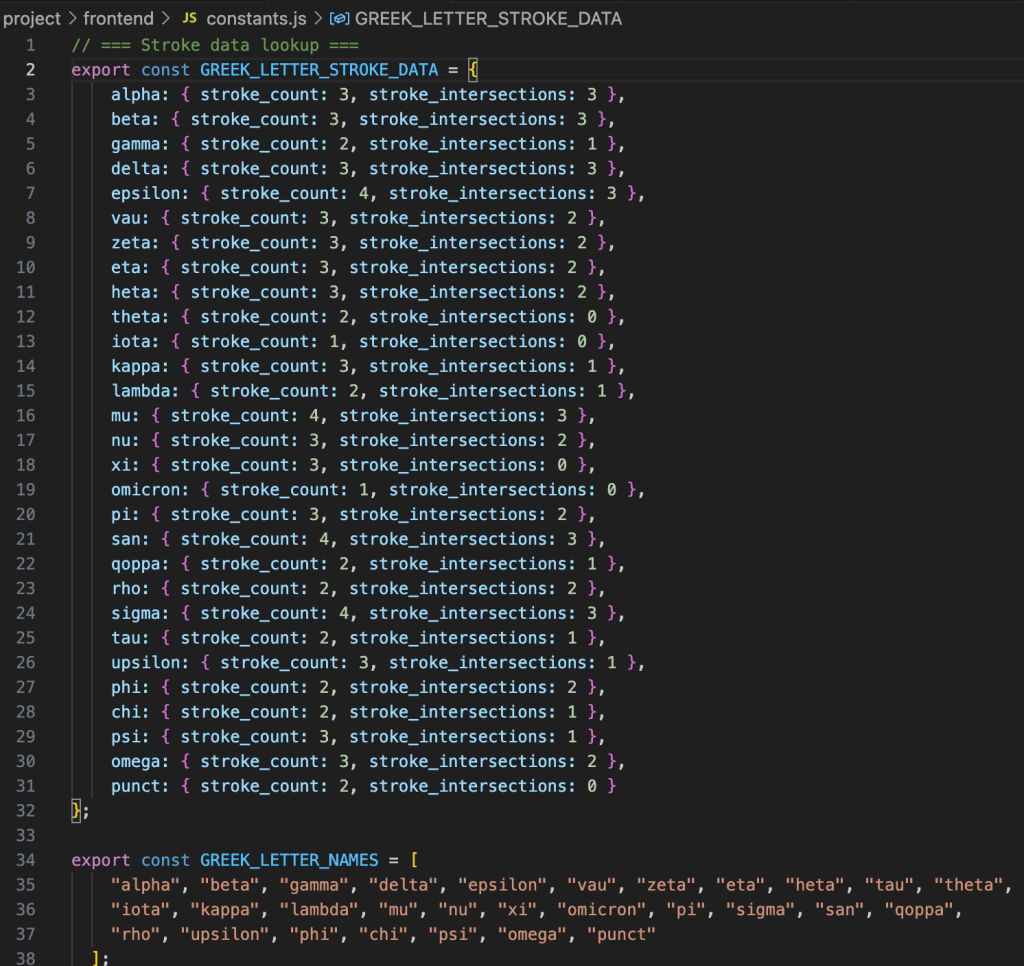
Five editable, language-aware dictionaries now exist for the GCELL script cluster, i.e., Greek, Coptic, Etruscan, Latin, and Lydian. There are another five dictionaries on the way for the PASHA branch: Phoenician, Aramaic, Semitic, Hebrew, and Arabian. This capability autofills letter names with their expected stroke and intersection counts, cutting per-glyph processing time by ~70%. These default expectations provide baselines for feature extraction and make visible the subtle divergences that define local or experimental hands.
The dynamic Greek dictionary.
5. From Interface to Insight
The combination of robust metadata, per-glyph fields, and structured dictionaries has turned APEX into a living research environment. A researcher can now import an object from a museum API, record multilingual metadata, define directionality, tag individual glyphs, and export a ready-to-analyze JSON file—all within a single interface.
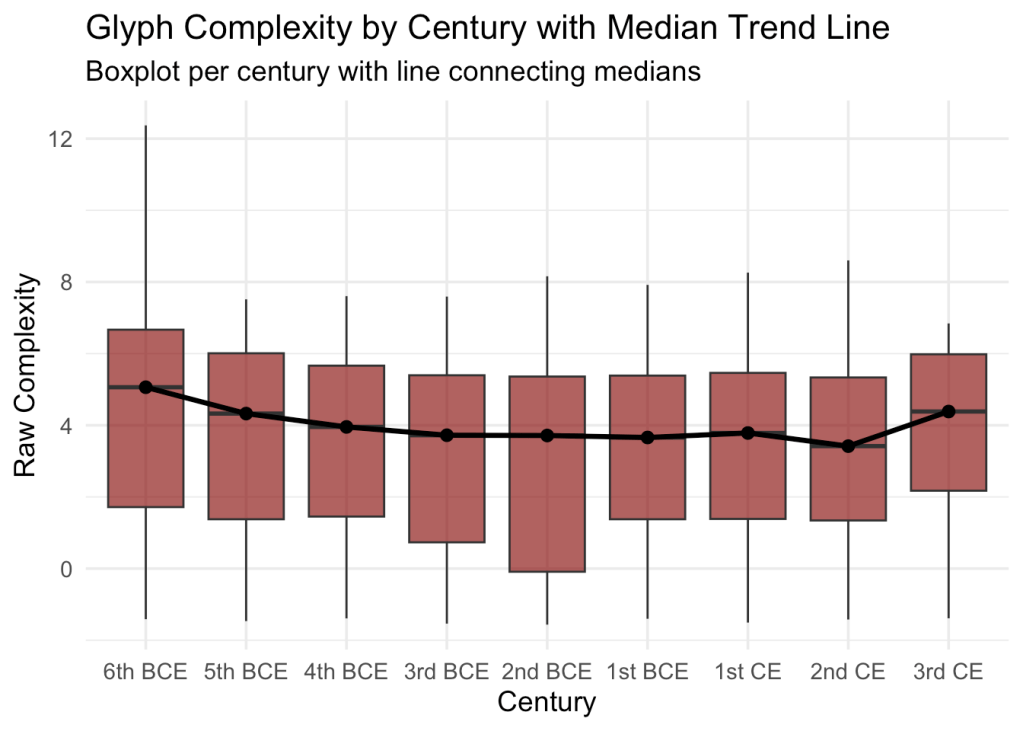
Early exploratory notebooks using the full eight-century dataset are already visualizing regional drift and stylistic convergence over time. Though not yet publishable, these models provide a first view of how letterforms move within and between centuries, forming clusters of continuity and outliers of innovation.
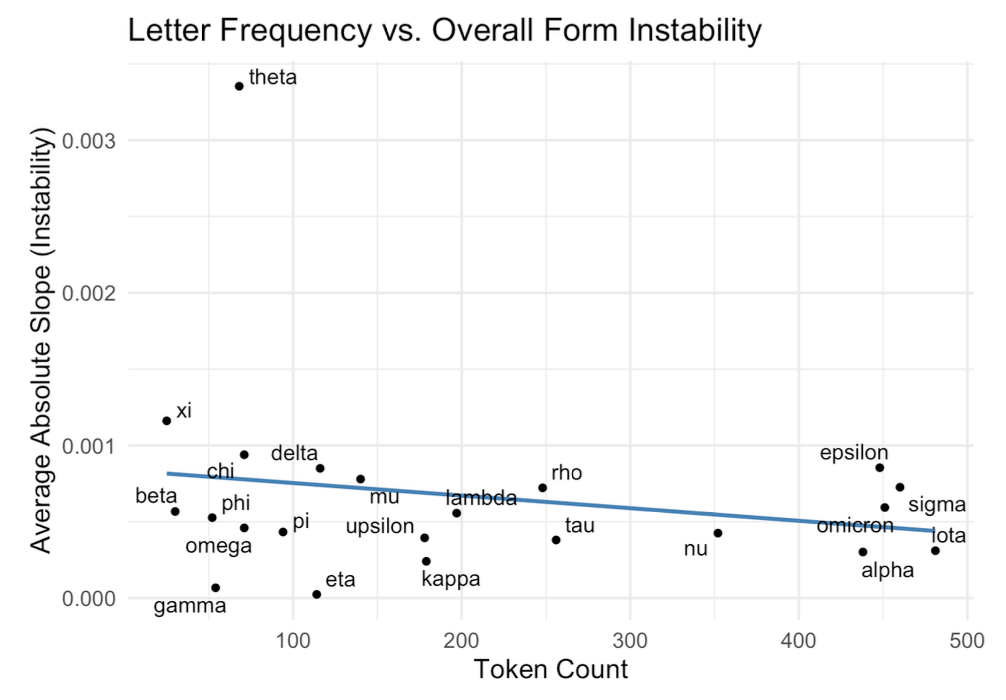
Critically, they also provide examples contrary to certain received wisdom. See the following chart, and note that the p-value of this correlation is p = 0.37, well above the <0.05 threshold for statistical significance in the social sciences.
In the eight-century dataset, letter frequency shows only a weak and statistically insignificant relationship to graphical stability. The trend line slopes slightly downward—more common letters like alpha, sigma, and omicron are somewhat more stable—but the effect is far from reliable. This suggests that the conventional linguistic expectation—that frequently used units remain more conservative—does not translate cleanly to letterforms. Here, stability may follow style and medium more than frequency.
6. Reflection
The major achievement of this phase is not simply scale—it’s integration. APEX has reached a point where drawing, data entry, and interpretation form a continuous loop. Each inscription is both a record of ancient writing and a record of modern reading.
With nearly five thousand glyphs from one major region already processed, APEX is beginning to reveal what paleographemics promises: the ability to study writing as a cultural system that can be seen, measured, and compared without losing its human texture.
I frequently get asked what classes to take if you want to work with ancient languages, inscriptions, museums, or language technology. This post is a reflection—not a blueprint—on how I’ve built a courseload that supports interdisciplinary work in epigraphy, historical linguistics, and digital tools, and what I’d recommend to others just starting out.
Start with the Languages (But Be Strategic)
If you’re reading this, chances are you already love ancient languages. So yes—take Latin. Take Greek. But if you have more than one on your list, resist the urge to take them all at once. Instead, start with one—preferably the one with the strongest institutional support—and stagger the rest. I did Latin in high school, Greek in my first year of college, and Akkadian in my second. That pacing gave me room to go deep into each one without burning out. Now, with that foundation, I’m able to handle several languages at the advanced level without losing clarity or joy.
If it interests you, try to take—or propose an independent study in—a language that uses a non-alphabetic script early on. Whether it’s cuneiform, hieroglyphs, or Linear B, working with a writing system that doesn’t map neatly onto speech will sharpen your sense of what writing is, how it encodes meaning, and how it changes across time. It will also raise questions—paleographic, technological, cognitive—that you may find yourself returning to long after the class ends.
Take Linguistics Early (You’ll Use It Constantly)
I’m biased—I’m a linguist—but even if you don’t plan to major in it, an intro to linguistics course will radically shift how you read ancient languages. You’ll start spotting things like vowel gradation, phonological assimilation, and case alignment everywhere. Once you’ve got the basics, courses like historical linguistics, syntax, or phonology can help you engage more confidently with scholarship and identify patterns in inscriptions, dialect variation, or reconstructed forms. Even if you don’t go further in formal coursework, just knowing the lingo goes a long way—and will keep paying off, quietly and consistently, across everything else you study.
Follow the Inscriptions and Those Who Teach Them
If you want to work with writing systems or epigraphy, find the people who do that at your institution. In this field, people often matter more than courses. Research your professors. Read what they’ve written. Faculty bios will give you a general idea of their focus, but their CVs are often more revealing—long, yes (I’ve seen them run 50 pages), but worth scanning for article titles and projects that align with your own interests.
Getting close to those key people might mean enrolling in something tangential—say, an intro to Greek art—just to build a relationship. Or asking if you can do an independent study reading inscriptions in translation. Some of my best classes weren’t labeled “epigraphy” at all—they were seminars where I was encouraged to bring paleographic questions into the final project. In one case, that was Data Science for Archaeology with Prof. Justin Pargeter, a course that shaped my thinking far beyond its original scope.
Think Across Disciplines, but Choose a Home
You’ll need a home base—a department that knows you, supports your work, and can write you letters. Having an intellectual anchor like that is not only strategic, it’s also deeply grounding. That said, your course list doesn’t have to stay confined to one department—and honestly, it probably shouldn’t. Academia is moving ever more toward interdisciplinary inquiry, and the best course of study often cuts across traditional boundaries.
Some of my most formative classes have been outside my major—art history, computer science, even religious studies (Akkadian lives in Judaic Studies at NYU). Let your questions guide you. If you’re wondering why Phoenician letters look the way they do, or what it means to “revive” a dead language, go find the classes that give you tools to explore those questions, wherever they live.
Just make sure you’re also building depth somewhere. Breadth can open doors—but it’s depth that gets you through them. Grad schools, mentors, and collaborators alike are looking for people who know how to ask big questions, but also how to sit with them for a long time.
Study Abroad, If You Can
There’s no substitute for learning ancient languages in place—or at least near the landscapes, museums, and excavation contexts where they come alive. Study abroad isn’t just about location; it’s about intensity, continuity, and community. My time in Greece, especially on digs and museum visits, made Greek less abstract and more human. It exposed me to a range of paths in classics and gave me access to resources—like fragmentary inscriptions in drawers—and rhythms, like reading in the field, that continue to shape how I think about epigraphy and transmission.
If you’re aiming for grad school or museum work, study-abroad experience shows initiative. It signals that you’ve navigated other academic systems, worked across language barriers, and engaged directly with material culture. If your program includes language immersion—even better. Even if the modern language isn’t your focus, it sharpens your ear and re-situates ancient texts as living inheritances.
If funding is a concern, don’t write it off. Many programs offer scholarships, and departments often quietly support students who ask early. At big schools like NYU, the key is often finding the right person—the one who knows how to unlock the support already available.
Don’t Be Afraid of Skill-Based Classes
If you’re anything like me, it’s easy to stay in the comfort zone of ancient texts and theoretical conversations. But some of the most valuable courses I’ve taken have been hands-on: digital humanities, data science, archaeological methods, computer science. These classes taught me how to manage a dataset, build a research tool, and think across evidence types. They’ve led directly to portfolio projects, study opportunities, and unexpected collaborations—and they’ve made my work in the ancient world more dynamic and durable.
Leave Room to Be Surprised
Some of my most formative classes were ones I hadn’t planned to take: a seminar on the topography and monuments of Athens (Prof. Robert Pitt), a deceptively simple primer in Greek archaeology that opened into real depth (Prof. Hüseyin Öztürk), and a course on the structure of the Russian language (Prof. Stephanie Harves). These were spaces where I tested my assumptions and rewired my thinking. Try to leave room in your schedule each year for one course that isn’t strictly “on track,” but that speaks to something curious or unsettled in you. That’s often where real questions begin.
Last Word: Plan Backwards
If you’re thinking about grad school or a research career, try working backwards. Look at the programs you might apply to—what do they expect? What languages, methods, or subfields appear in course requirements or faculty research? Then take classes that prepare you for those conversations. The goal isn’t to become someone else’s version of a scholar—it’s to become the version of yourself who belongs in the rooms you want to be in.
Closing
When in doubt, ask people. Older students, professors, internet strangers who study Linear B. This path isn’t something I mapped out alone—almost every turning point in my academic life has come from a conversation, an offhand recommendation, or a generous reply to a cold email. I’ve built my way forward through the advice of others, and I’m always happy to pay it forward.
In a follow-up post, I’ll share how to structure independent study: designing personal projects, sustaining long-term reading, and building a research portfolio beyond the classroom. Done well, this kind of work lets you follow your own questions, test your interests, and create something distinctly your own. It’s also one of the clearest ways to show grad schools and mentors that you know how to learn without a syllabus.
Stay tuned. And as always, if you’re not sure where to start, I’d love to hear what you’re thinking about.
Akkadian is a Semitic language written in the cuneiform script, with texts ranging from royal inscriptions and law codes to letters, contracts, and epics like Gilgamesh. This toolkit gathers the core resources I use to study the language, from mastering the sign list to parsing verbal forms. Whether you’re preparing for graduate study, brushing up for a seminar, or just drawn to the richness of Mesopotamian literature, these are the tools that ground my work with Akkadian.
A quick note: some of these are in German and French, and of course not everyone reads those. However, Google Translate handles them very well if you upload a screenshot of a paragraph, and as my modern languages are not the strongest yet, I’ve found it invaluable. Use this link to access.
Huehnergard – A Grammar of Akkadian The most widely used modern introduction to Akkadian, especially for Old Babylonian. Combines clear grammatical explanations with exercises, paradigms, and a reading sequence. Thorough and approachable. Read online
Caplice – Introduction to Akkadian More compact and reference-oriented than Huehnergard, with streamlined grammar sections and bilingual text readings. Works well as a complement or for review. Read online
Labat – Manuel d’épigraphie akkadienne: Signes cunéiformes, syllabaires, idéogrammes The definitive sign list for Akkadian cuneiform. Includes syllabic values, logograms, variant shapes, and transcription equivalents. Indispensable when reading from tablets or facsimiles. Read online
Digital Tools
ePSD2 (The Electronic Pennsylvania Sumerian Dictionary) Although primarily for Sumerian, ePSD2 is invaluable for logogram glosses and cross-referencing Akkadian readings of signs. Frequently cited in scholarly work. Access online
ORACC (Open Richly Annotated Cuneiform Corpus) A massive and expanding corpus of annotated Akkadian texts in transliteration and translation, with tools for exploring morphology, genre, and metadata. Excellent for seeing how grammar functions in real texts. Access online
Wiktionary There is no single definitive online Akkadian dictionary, but entries on Wiktionary can help with basic word lookup in transliteration. Access online
Advanced Topics
Von Soden – Grundriss der Akkadischen Grammatik The classic grammar of Akkadian, written in German. Highly detailed, especially in verbal system analysis and historical variants. Read online
Goetze / Landsberger – Text Editions Once you’ve completed initial grammar work, reading annotated text editions from scholars like Goetze or Landsberger will help solidify your grasp of style, genre, and dialect variation.
Conclusion
This toolkit focuses on Old Babylonian and Standard Babylonian as the primary dialects, but the resources here will give you enough flexibility to branch into Assyrian, Middle Babylonian, and other variants. Akkadian is a richly inflected language with a complex writing system, and the path to fluency is best grounded in patient sign recognition, morphological fluency, and careful reading.
These are the resources I’ve found most helpful in learning and returning to Akkadian. If you know of other tools or have advice from the field, I’d love to hear what’s missing.
The next portion of Tools of the Trade will focus on a series of “core toolkits” for a variety of languages. These will be linked here as they roll out over the next few days. The first five, in order, will be:
If any more are added, I’ll link them here as well. I’m planning on doing Phoenician and Middle Egyptian at some point, and maybe even posts on families, probably Semitic and Indo-European. After that, there will be two more posts on epigraphic tools, followed by a series of computational ones, and then probably some meta-tools (e.g., guides to digital organization, etc.). After that it’s anyone’s game, and I fully welcome suggestions. Feel free to email me here if there’s anything you’ve been wanting to get into but haven’t found good resources for.
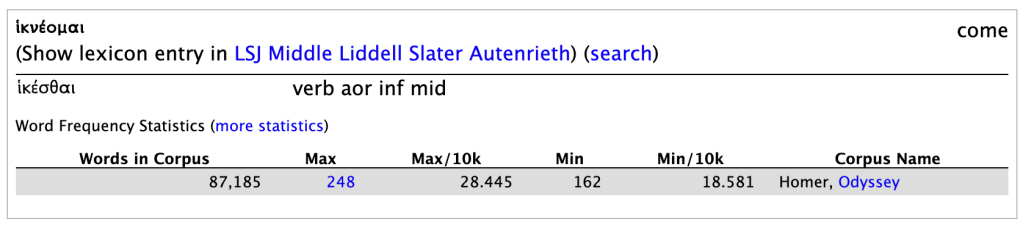
Perseus’s result for ἱκνέομαι: a quick parser, giving form and summary of corpus occurrences.Partial Logeion result for the same word: collates detailed results from nine separate dictionaries with a 10th tab for corpus occurrences.
For anyone studying Latin or Ancient Greek—whether casually, academically, or obsessively—two digital tools stand out as indispensable: Perseus and Logeion. I use both almost every day. While they serve overlapping purposes, each has its own strengths, and learning to navigate between them has made my reading smoother, faster, and more precise.
Perseus, formally known as the Perseus Digital Library, is one of the earliest and most ambitious digital humanities projects in the field of Classics. It provides access to a massive collection of Greek and Latin texts with built-in parsing tools, dictionary links, and (often outdated but still helpful) English translations. Its strength lies in contextual reading—hovering over any word in a text will generate a parsing suggestion and a link to its dictionary entry, which makes it incredibly useful when working through a new author or a grammatically complex passage. The Word Study Tool allows you to input any inflected form and get a list of possible morphological analyses and dictionary headwords, with links to example passages. However, it’s important to note that these parsings are generated by algorithms and are not always reliable, especially for ambiguous forms. The interface can also feel a bit dated, and not all texts are equally well formatted, but for quick reading and parsing, Perseus is great.
By contrast, Logeion is a sleek and powerful lexicon aggregator developed by the University of Chicago. Unlike Perseus, it doesn’t offer complete texts, but it excels at lexical depth. When you enter a word—either in Latin or Greek—Logeion pulls results from multiple dictionaries at once, including LSJ, Middle Liddell, Autenrieth, Lewis & Short, Elementary Lewis, Frieze-Dennison, and others. You also get frequency data, example passages, and, in some cases, idiomatic usages or English-to-Greek reverse entries. Logeion doesn’t parse for you, so you need to know or guess the dictionary form of the word. But once you do, the definitions it offers are more precise and informative than any single dictionary alone. I often use it to compare lexical nuance across genres or authors, and it’s especially helpful when I want to confirm the meaning of a word I already sort of “know.”
The way I use these two tools in tandem is pretty straightforward. When I’m reading through a text, especially something new or poetic, I usually begin in Perseus. I use the on-hover parsing and the Word Study Tool to get oriented, especially with verbs and particles. Once I have the base form, I switch over to Logeion to dig deeper into meaning, idiom, or usage across contexts. Logeion becomes especially helpful when I’m writing, translating, or thinking more syntactically. In many ways, Perseus is like a field guide with helpful margin notes, while Logeion is the serious reference work you turn to when you want to be exact.
If you’re just starting out, don’t feel pressured to master everything at once. But learning to toggle between Perseus and Logeion will give you a huge advantage—especially if you’re not always reading with a print dictionary on hand or don’t have institutional resources. I’ve used these tools for years—they’ve remained central across every stage of my study. They’re fast, free, and surprisingly deep once you know where to look.
If you’ve found tricks for using them more efficiently, or if you have a favorite feature I didn’t mention, let me know what’s missing.
Process for entering the metadata of a given inscription in the GUI I’m designing.
Before APEX can tell us anything about the shapes of letters, we have to tell it what those letters are—where they came from, when, how confidently we know that, and why we think so. Each traced form in the database is embedded in metadata, and each metadata field is a choice. Or, more accurately, a battleground between competing demands: standardization vs. specificity, precision vs. honesty, completeness vs. clarity.
This post is about how those choices get made.
Metadata is Never Neutral
In paleographic projects, metadata is often treated as scaffolding: a tidy column of site names, dates, scripts, and references that supports the real work of analysis. But metadata is also where the most important theoretical decisions live. Is this letter from “Attica” or from “Athens”? Is it dated to “c. 750 BCE,” to “the mid-8th century,” or to “LG I”? Is the script “Euboean” or “Eubo-Cypriot” or just “Greek”? And what happens when those terms carry more ambiguity than certainty?
Each of these choices folds a story into the dataset. A story about geography, chronology, authority, and classification. And once the data is encoded, those stories begin to function as fixed facts—however uncertain or contingent they might actually be.
The Problem of Uncertainty
Uncertainty is endemic to early alphabetic evidence. Sites are excavated unevenly. Inscriptions are fragmentary. Provenance can be speculative. Paleographic dating relies on a mix of typological comparison and stratigraphy, both of which are prone to revision.
But digital systems, including APEX, are uncomfortable with uncertainty. The data model wants a number, not a range; a site name, not a narrative; a script label, not a conditional. This means encoding decisions often involve collapsing complexity into legibility. The trick is to do this transparently, and to leave enough of a trail that the uncertainties can still be seen.
To that end, I’m building out APEX metadata with fields for:
Script classification (source + variant): to distinguish between modern typologies and how scripts were likely conceived by ancient users
Notes: a catch-all for uncertainty flags, alternate readings, or disputed attributions
This structure still imposes a frame, but it tries to make the cracks visible.
Metadata as Narrative
Every field in APEX is a decision, and every decision reflects a point of view—whether archaeological, linguistic, technological, or historiographic. That makes the metadata not just a scaffold but a narrative: a set of assumptions about what kind of thing the alphabet is, how it moves through space and time, and how we can know what we know. As the project scales, that narrative will shape what kinds of conclusions are possible. So I want to make it visible now, while it’s still under construction, as part of the work.
In the next update, I’ll cover the baseline nature of the pipeline and what makes it so difficult—but also so precise.
Nestor’s Cup (Pithekoussai, modern Sicily) & Dipylon Inscription (Athens), both dated just after 750 BCE.Three famous Phoenician inscriptions, of various dates, to compare letterforms to the above.
If the first APEX post was about tracing letters, this one is about why those traces matter. Underneath every variant alpha or eccentric epsilon is a deeper question: when, how, and under what conditions did the Greek alphabet emerge from its West Semitic predecessor? This question, which is known in the scholarship as the transmission problem, lies at the core of alphabetic studies, and despite over a century of scholarship, it remains fiercely contested. To map alphabetic transmission is not just to track graphical similarity, but to reckon with how cultures borrow, adapt, forget, and reimagine the systems by which they make language visible.
At its simplest, the transmission problem asks: When did the Greeks adopt the Phoenician script? But the real terrain is messier. Did the transfer happen once or multiple times? Was it sudden or gradual? Coordinated or ad hoc? Which region of the Greek-speaking world was first? Exactly which Semitic script was the donor—or was there a confluence of models? And what kind of evidence—linguistic, paleographic, archaeological—should we privilege when our sources conflict?
Historically, the debate has followed disciplinary lines. Scholars trained in Semitic philology and Near Eastern studies tend to favor a high date for the transmission: sometime in the 11th or 10th century BCE, before the traditional Greek Geometric period (in older scholarship, referred to as the “Greek Dark Age”). This camp emphasizes the strong formal similarities between early Greek and Phoenician letterforms, arguing that Greek epichoric scripts most closely resemble Phoenician forms from around 1050 BCE, not the later shapes one would expect if transmission occurred in the 8th century. Joseph Naveh, for instance, in his landmark Early History of the Alphabet (1982), argued that the Greek system must have branched off before major innovations appear in the Phoenician script, such as the angular mem or evolved forms of shin. Naveh saw the Greek alphabet as a snapshot of an earlier Semitic system—evidence, in his view, of early contact and early borrowing.
On the other side of the debate, Classicists and archaeologists tend to argue for a low date, favoring the 8th century BCE. Their reasoning draws primarily from stratified archaeological contexts: the earliest securely datable Greek inscriptions—such as the Dipylon oinochoe and the Nestor’s Cup from Pithekoussai—belong to the mid-to-late 8th century. Rhys Carpenter was among the earliest and most forceful voices in this camp. In a 1933 article, he wrote that “the argumentum a silentio grows every year more formidable and more conclusive,” referring to the continued absence of any Greek alphabetic inscriptions predating the eighth century (“The Antiquity of the Greek Alphabet,” AJA 37 [1933]: 8–29, at p. 27). For Carpenter, the lack of material evidence was not a gap to be explained away, but itself a powerful datum: if earlier use had existed, we would likely have found traces by now.
This school is generally skeptical of typological comparison, pointing out that letterforms evolve unevenly and can be conservative in certain contexts. Archaeological absence, while never conclusive, is taken seriously—especially when paired with the sudden, near-simultaneous appearance of inscriptions across disparate sites in the 8th century, suggesting a relatively rapid uptake of a recently acquired script. Later scholars, such as Barry B. Powell, built on this foundation. In Homer and the Origin of the Greek Alphabet (1991), Powell controversially argued that the Greek alphabet was deliberately invented for the purpose of recording Homeric verse, dating the invention to around 750 BCE. Though widely criticized for its teleology and lack of evidence for such a top-down design, Powell’s theory exemplifies the kind of interdisciplinary crossfire that defines this problem: where linguistic function, archaeological data, and cultural ideology all collide.
Roger D. Woodard, in Greek Writing from Knossos to Homer (1997), pushed back against Powell while still supporting a relatively late date. Woodard views the alphabet’s adaptation as a process shaped not only by contact with Phoenician traders but also by internal Greek developments—especially the memory of Linear B and broader shifts in literacy practices. He emphasizes the complex interplay between tradition and innovation, seeing the Greek vowel system as a structural solution that could only emerge in a linguistic environment receptive to phonological precision.
The question remains open, but APEX offers a different kind of approach. Rather than anchoring the debate to a single origin point, I focus on regional trajectories and graphical evidence: how letterforms vary, travel, and settle. If the Semitic party line reads the Greek alphabet as a photograph of Phoenician forms from 1000 BCE, and the archaeological model sees it as an emergent public tool of the 8th century, then I want to understand how specific graphemes move through space and time. Which forms remain stable across centuries? Which mutate rapidly? And what can that tell us about the process of transmission, rather than the moment of origin?
In fact, the most immediate goal of the APEX project is to evaluate whether the Greek letterforms do, in fact, most closely resemble the Semitic models from around 1000 BCE—as the high-date camp maintains—or if their nearest parallels lie elsewhere in the Phoenician typology. The intention is to move beyond qualitative comparisons and scholarly intuition, toward a quantitative, statistically grounded assessment of letterform similarity. By measuring and modeling these visual relationships systematically, APEX aims to provide a more objective foundation for dating the moment of greatest resemblance between the Greek and Phoenician scripts.
Rather than jumping straight into letterform similarity metrics, though, the next update will take a detour—one that’s no less crucial. Before the vectors can speak, they must be named, contextualized, and organized. APEX Updates, 3: Encoding Decisions will explore how I’m structuring the metadata that surrounds each traced letter: what counts as “context,” how information is tagged, and why every dataset is also a narrative. As it turns out, deciding how to describe a letter may be just as revealing as deciding how to compare it.
The Parthenon/Elgin Marbles as in the British Museum, London.
Diaspora means a scattering—but not just away from. It’s also a scattering into: people of yours wherever you go. There’s dislocation in that, but also a strange kind of belonging. You’re never quite at home, but also never entirely foreign. We are at home wherever we are, as the Jewish Bundists say.
I come from the Armenian diaspora. Much of the history I now hold came to me late, in fragments I had to gather myself. So much so that when my family went to Armenia for the 100th anniversary of the genocide, I misunderstood the purpose of our trip. I didn’t yet know what had been left unsaid. I learned the truth online months later. A strange inheritance: delayed, then all at once.
That moment formed something in me—something about responsibility, memory, and the ethics of knowing. I now see myself as a banner-carrier of the diasporic experience—not just for Armenians, but in solidarity with all displaced and fragmented peoples. Diaspora isn’t a single story but a way of listening, noticing, and asking better questions.
Ironically, none of the languages I study are mine. I never learned Armenian. I was meant to attend an immersion program in Yerevan in 2020, but it didn’t happen for the obvious reasons. The language now feels like an island—real, reachable, and still far away. It’s typologically unusual and hard to access. And emotionally, I’ve kept it at a distance—not for lack of interest, but for fear of doing it harm.
Still, the connection shows up. It’s in the care I bring to other people’s histories, in my reverence for displaced traditions, in my work with Semitic languages—speech communities so often marked by rupture. I haven’t yet studied heritage material from my own background, but I carry the stakes of diasporic scholarship into every archive. Distance doesn’t cancel care, it clarifies it.
My sense of scholarly ethics—especially around archaeology and epigraphy—grows directly from this. I believe in repatriation, in collective self-determination and the right of communities to steward their past. Yes, nations are imagined, but so are all our systems of meaning. So long as national identity structures the world, its claims must be taken seriously.
Museums, of course, complicate things. Scattering brings both access and erasure. Greek artifacts in London, Mesopotamian seals in New York—these too live in diaspora. There’s value in broader visibility, especially for those who can’t travel. But there’s loss, too: of voice, of sovereignty, of situated knowledge. I think about this often. I haven’t resolved it.
I don’t just want a life in the library. I want antiquity to be for everyone. I want the past to feel shared, common, alive. I want to show people that our inheritance—linguistic, cultural, intellectual—is truly ours. The more we realize that, the more fully we can meet the present. That’s the gift of diaspora: a way of being scattered that still insists on connection.
The Parthenon Marbles as in the Acropolis Museum in Athens. Every time I’ve visited, it’s struck me as a monument to loss.
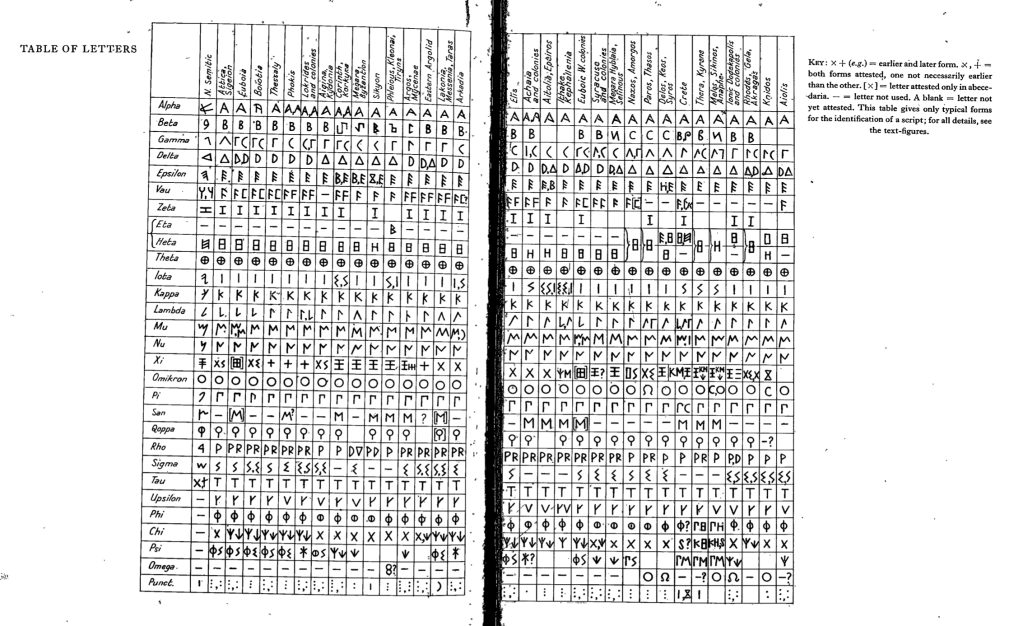
Jeffery’s summary table of all epichoric scripts at the end of LSAG. It is foundational for any work on early regional Greek scripts.
There are very few books I consider truly irreplaceable in my research. Lilian H. Jeffery’s The Local Scripts of Archaic Greece is one of them. First published in 1961 and revised in 1990 with A.W. Johnston, this book remains the reference for regional variations in the Greek alphabet during the archaic period. It’s where I first learned to read epichoric inscriptions with the eye of a paleographer rather than a Classicist alone.
The book is very hard to find, and I only got my copy at an even remotely affordable price after months of scouring secondhand sellers. While copies still circulate among libraries and the used book market, I wanted to make it more accessible to others working in this area. So I hunted diligently before finding it on the Internet Archive. You can read or download it here: The Local Scripts of Archaic Greece (1990 ed.) – Internet Archive
Jeffery’s study remains foundational for any work on early Greek writing—not just in Athens or Ionia, but across the full spectrum of regional scripts: Corinthian, Euboian, Attic-Boeotian, Cretan, Cycladic, and others. It includes extensive commentary, maps, and an invaluable inscriptional catalogue organized by region, with drawings and typographic transcriptions. The 1990 revision added important corrections, expanded references, and additional illustrative material. For those of us studying alphabetic transmission, especially the Phoenician-Greek interface or the evolution of letterforms over time, this book is indispensable.
What makes Local Scripts especially useful is that it bridges the gap between paleography, archaeology, and linguistics. Jeffery doesn’t just chart when and where a particular variant of alpha or epsilon shows up—she explains what those variations might imply for chronology, influence, and contact. And although her typology has been revised and challenged in places (especially with the discovery of new inscriptions), her system remains a critical baseline for almost every study that’s come after.
Whether you’re interested in early Greek literacy, the transmission of the alphabet, the sociopolitical meaning of epigraphy, or just want to be able to tell the difference between Laconian and Euboian chi, this is the book to start with. I hope having it freely available will be helpful to others navigating this fragmentary and fascinating material.
Do you have other resources you pair with Jeffery? I’d love to hear what we can supplement LSAG with.