The Vision and the Bottleneck

Hours pass like this: bent over an iPad image, tracing one letter after another. Each alpha, each resh, becomes a small act of care—lines pulled taut, cleaned, bounded. It’s a ritual, somewhere between drawing and deciphering, between study and touch.
But beneath that ritual lies a bottleneck—the invisible labor of segmentation. Before any computer can analyze a letter, someone has to isolate it: to draw a box, to declare this is glyph and that is background. It’s the unseen threshold of every computational paleography project. The machine cannot learn to read until it can first learn to see.
That’s the problem and the promise. If I can teach the system to segment inscriptions automatically, with epigraphic precision, the entire pipeline changes. What has so far depended on human dexterity could become scalable without losing rigor. The ambition is simple to state, and enormous to achieve: to automate attention.
Automating Attention
Segmentation, in plain terms, means teaching the computer to draw invisible boxes around ancient letters. It sounds trivial, but it’s the hinge between archaeology and AI, between artifact and data. Every analysis I’ve ever run on symmetry, complexity, or transmission rests on that first act of demarcation. Without it, nothing else holds.
Computational paleography has come far in feature extraction, clustering, and visualization. But segmentation remains human-bound, a couture craft disguised as mechanical preprocessing. To “close the loop”—to move from semi-automated annotation to a genuine vision pipeline—is to let the system begin where I do: by noticing.
This, then, is the next frontier of APEX: dexterity to detection.
Teaching the Machine to See Like an Epigrapher


Segmentation is difficult not because machines are bad at vision, but because ancient writing is not meant for them. Lighting varies; stone gleams or shadows; lead reflects; letters fade into corrosion or merge in ligature. Scripts mutate, overlap, and misbehave. Non-Latin alphabets, especially, resist the tidy categories on which modern OCR depends. The machine expects Helvetica. What it gets is Styra.
Traditional OCR fails here because it assumes clean, printed forms—typographic regularity, not weathered intent. An epigrapher reads not just the mark but the gesture that made it. To approximate that sensitivity computationally is less about brute accuracy than about modeling discernment.
At present, APEX’s dataset contains roughly 2,000 glyphs across 50 inscription photos—each traced and annotated by hand. Those drawings are not just data; they are training material. They encode what human attention looks like when applied to ancient form.
The great tension ahead lies between fidelity and generalization: the need to preserve nuance while building a model that can scale. Building a dataset is a kind of digital fieldwork: slow, repetitive, and quietly devotional.
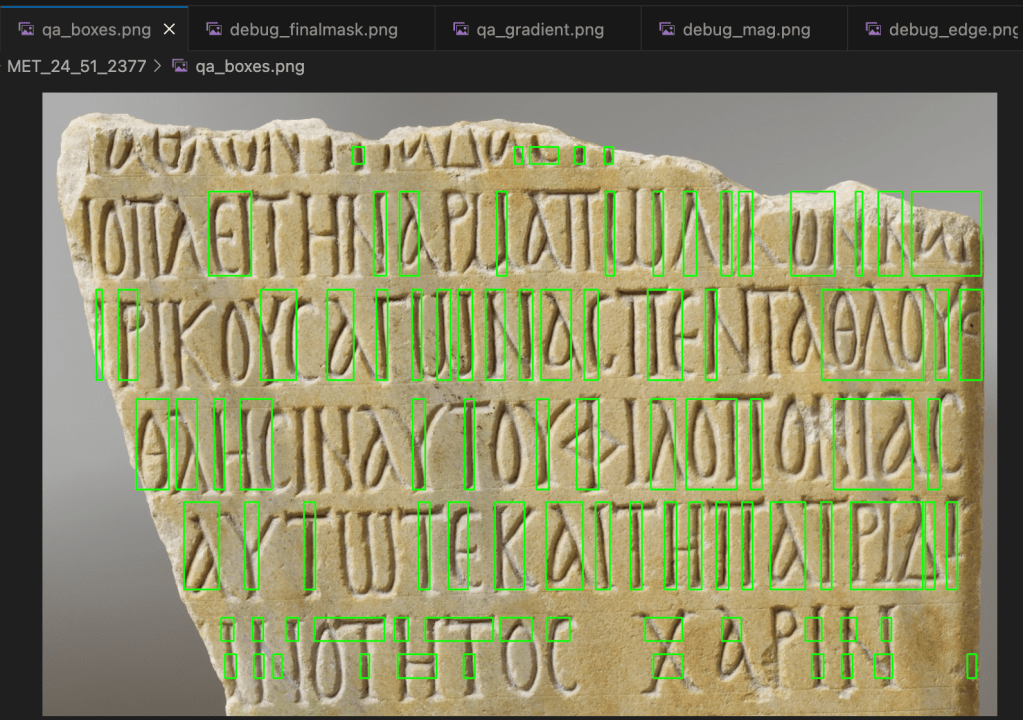
Building Iteratively
Phase 1 — Manual Baseline
Create high-quality, human-annotated bounding boxes—each verified against the traced vectors. Establish a consistent schema: filenames, rights metadata, feature tables. This becomes the ground truth. Approximately 1/5 through my 10k glyph goal.
Phase 2 — Model Prototyping
Train a small (YOLOv8 perhaps) segmentation model on the initial 2k glyphs. Evaluate precision and recall. Visualize false positives and negatives. Adjust preprocessing—normalize lighting, sharpen contrast, calibrate thresholds.
Phase 3 — Iterative Retraining
Adopt a human-in-the-loop cycle. The model proposes and asks for clarifications; I correct and feed it the new data it needs in an active learning process. Those corrections return to the model as new training data. Each iteration, where I feed it 1k glyphs more at a time in targeted passes, improves both speed and fidelity.
Phase 4 — Integration with APEX
Fold the trained segmenter into the APEX engine. Users will be able to run it locally or via API, generating structured, IIIF-ready outputs. The dashboard will visualize segmentation confidence and quality metrics in real time.
Phase 5 — Cross-Script Generalization
Extend beyond Greek: Phoenician, Aramaic, Lydian, Coptic, and others. Develop shared feature ontologies for cross-script comparison. The horizon: a universal segmentation model for alphabetic writing.
What It Means to Eliminate a Bottleneck
To automate segmentation is not to replace the human but amplify what the human can attend to. The dream isn’t delegation but acceleration: letting the machine perform the gestures that would otherwise consume a lifetime, so that we can ask better questions.
The act of teaching a model to see is, in a way, an act of translation. Between disciplines, between forms of attention. APEX began as a bridge between ancient and digital worlds; this next stage extends that bridge into vision itself.
If segmentation is the bottleneck, then teaching the machine to see is the act of undamming the throat of the alphabet—to let the dead speak again, not in whispers, but in full computational voice.



