Clarice from Calvino’s Invisible Cities, as drawn by Karina Puente.
In the last decade the digital humanities have built an ethics of stewardship around two frameworks: FAIR and CARE.
Data, we’re told, should be Findable, Accessible, Interoperable, Reusable; its use should uphold Collective benefit, Authority to control, Responsibility, and Ethics. These principles have given structure to a once-couture, even cowboy, practice. They taught us that visibility is a virtue, that openness can be an act of justice. They made data management legible—something one could rate, certify, or defend.
Yet legibility is never neutral. FAIR presumes that clarity is the highest good; CARE assumes that control can be cleanly assigned. Both, however gently, rest on the dream of completeness: that if we organize our data well enough, we might finally see the whole.
APEX lives where that dream dies. The inscriptions I trace resist closure. They are fragmentary, re-inscribed, half-lost. Every dataset carries the tremor of its source—a chipped delta, a missing ‘alep, a surface that refuses to yield. The data, like the stones themselves, is frail.
I’ve begun to imagine a third paradigm: one that keeps FAIR’s discipline and CARE’s ethics but admits that in the humanities, stability is fictional. Call it FRAIL: Findable, Reproducible, Accountable, Interpretive, and Liminal.
Findable—disappearance helps no one.
Reproducible—others should be able to retrace our steps, even if they find another path.
Accountable—provenance and responsibility cannot be dispensed of.
Interpretive—ambiguity, when recorded, becomes part of the evidence itself.
Liminal—some knowledge dwells on thresholds: certainty and speculation, artifact and idea.
FRAIL doesn’t replace FAIR or CARE but grows from them. It asks what stewardship looks like when the object of study is itself uncertain, when our task is to hold the fragment without pretending it is whole.
At this point I keep returning to Calvino’s Invisible Cities. In “Cities and Names 4,” he writes of Clarice, a city that forever rebuilds itself from the shards of its earlier selves:
“Only this is know for sure: a given number of objects is shifted within a given space, at times submerged by a quantity of new objects, at times worn out and not replaced; the rule is to shuffle them each time, then try to assemble them. Perhaps Clarice has always been only a confusion of chipped gimcracks, ill-assorted, obsolete.”
Clarice is every archive we have ever built. Its fragments persist, rearranged with each generation, their order provisional, their meaning renewed by use. FRAIL data lives in that same condition: never whole, yet never lost—structures of care built from what survives. The humanities have always been a discipline of rebuilding Clarice.
To keep data FRAIL is therefore not to weaken it but to recognize its true strength: the capacity to bear transformation without disowning its past. Rigor becomes a form of tenderness. Reproducibility includes hesitation. The dataset, like the inscription, becomes layered, self-aware, and open to rereading.
In APEX I try to move toward that kind of data: technically precise yet narratively honest, transparent about its mediation, willing to show its seams. The goal isn’t immortality but traceability—to make each decision legible without pretending it ends the story.
Perhaps that is what stewardship finally means: not to eliminate fragility, but to hold it safely, as one holds a fragment of Clarice—knowing it has already been broken, and still believing it can be assembled again.
An example of gold lacquerware: it loses something in the harsh light of the catalogue. .
When I was fifteen, I read Jun’ichirō Tanizaki’s In Praise of Shadows without knowing how to name the unease it stirred. I didn’t yet have a project or a discipline, only a sense that technology could be moral in its texture. Even a lamp carries a worldview. Every act of design answers a metaphysical question: what do we think knowledge should look like?
What would a washing machine look like if designed from within a Japanese sensibility rather than imported Western logic? A fountain pen? A bathroom?
Years later, as I train segmentation models and debug recursive loops, I keep thinking about that line. I’ve started to wonder what a machine built from a Middle Eastern sensibility would look like—what it would mean to design software from within the epistemic lineage that produced the alphabets I study, to work from my own heritage as a Middle Eastern researcher myself.
Shadow-Aware Programming
So much of American computer science assumes that clarity is the highest good: explicit is better than implicit, errors must be handled, uncertainty resolved. It’s a worldview of grids, graphs, and proofs, of light without shadow. Even our metaphors for computation—pipelines, flows, stacks—presume continuity and containment.
The world APEX studies was never built that way. The alphabets that seeded Greek writing came from cultures that held multiplicity as a form of precision. Meaning could live in the margin, in the half-seen ligature, in the polyvalence of a single sign. In those traditions, opacity was structure. The text was not a window. Knowledge emerged through relation rather than reduction.
When I look at my code through that lens, I see just how Western its instincts are. Every line by its nature insists on disambiguation; every model optimizes for convergence. What would it mean to build a system that allowed divergence to count as truth?
A Patinated Algorithm
APEX has been my laboratory for this question. Each stage of the pipeline forces me to choose between clarity and care.
American frameworks reward closure: every function must return a value, every process must resolve. But paleography resists closure. The most honest state is, often, a definite maybe. I’ve built APEX’s schemas to accommodate that—to let “uncertain,” “variant,” and “disputed” be valid outputs, not placeholders for failure.
The result is a dataset that behaves more like a commentary tradition than a database: multiple voices, layered readings, recursive disagreements. It’s an architecture of coexistence, a Talmudic litigation of love. In its small way, APEX tries to reintroduce that Middle Eastern mode of knowledge: the one that assumes that understanding doesn’t replace mystery but deepens it.
Inheritance and Interference
This isn’t a manifesto against computation. It’s a recognition that computation, as I’ve encountered it in the American university system, carries unspoken moral premises: that a problem can be solved, that noise can be filtered, that ambiguity is a bug.
But the alphabet itself was a product of a world where those premises didn’t hold. The Phoenician scribes who first shaped letters into repeatable forms were negotiating between sound and sign, god and stone. Their writing system was a compromise between the seen and the said.
When I import their traces into Python scripts and JSON schemas, I feel that interference—the hum between two epistemologies. One seeks light, the other shadow. One builds toward universality, the other toward particularity. APEX lives in that interference pattern. It’s less a reconciliation than a coexistence.
Learning to Code Otherwise
Building a model from a Middle Eastern epistemology doesn’t mean using “Eastern data” or aestheticized, exoticized metaphors. It means rethinking what the model owes to its object. It means writing code that holds its own uncertainty—that treats silence, loss, and contradiction as data types.
I’ve been experimenting with forms of graceful incompletion, so to speak: workflows that stop short rather than forcing a decision, algorithms that surface disagreement instead of averaging it out. I’ve even started thinking about whether uncertainty could be rendered visually—whether the model’s hesitation could be made visible, like a faint shadow under each bounding box. Confidence intervals are a start. I want to take it further.
It feels strange, almost perverse, to build a machine that admits it doesn’t know. But perhaps that’s what ethical technology for the ancient world should look like: something provisional, interpretive, humble enough to remain unfinished.
The Long Continuity
Looking back, this thread has been there since the beginning. Encoding Decisions asked how metadata carries ideology. The Pipeline Problem wrestled with the impossibility of full automation. Teaching the Machine to Read turned that impossibility into method—training the computer not just to recognize letters but to inherit human hesitation.
“Designing in the Shadows” is another turn of that screw. The question now is not how to teach the machine to see, but how to teach it to doubt.
Maybe that’s what it means to build from the epistemology of the alphabets themselves. Treat uncertainty as the condition of meaning.
Coda
Tanizaki wrote that “were it not for shadows, there would be no beauty.”
In American computer science, we’re taught the opposite: that shadow is error, that beauty lies in perfect visibility.
But my work lives somewhere in between. Every day I toggle between these grammars of knowing—between the brightness of the machine and the opacity of the inscription.
If In Praise of Shadows sought a cultural continuity within modernization, perhaps APEX is seeking a moral continuity within computation. I hope, at least, to leave a trace of that other way of seeing—
A system that illuminates, but never over-illuminates.
A technology that leaves the dead a little privacy, while still letting them speak.
A manually vectorized, and therefore easily segmented, inscription.
Hours pass like this: bent over an iPad image, tracing one letter after another. Each alpha, each resh, becomes a small act of care—lines pulled taut, cleaned, bounded. It’s a ritual, somewhere between drawing and deciphering, between study and touch.
But beneath that ritual lies a bottleneck—the invisible labor of segmentation. Before any computer can analyze a letter, someone has to isolate it: to draw a box, to declare this is glyph and that is background. It’s the unseen threshold of every computational paleography project. The machine cannot learn to read until it can first learn to see.
That’s the problem and the promise. If I can teach the system to segment inscriptions automatically, with epigraphic precision, the entire pipeline changes. What has so far depended on human dexterity could become scalable without losing rigor. The ambition is simple to state, and enormous to achieve: to automate attention.
Automating Attention
Segmentation, in plain terms, means teaching the computer to draw invisible boxes around ancient letters. It sounds trivial, but it’s the hinge between archaeology and AI, between artifact and data. Every analysis I’ve ever run on symmetry, complexity, or transmission rests on that first act of demarcation. Without it, nothing else holds.
Computational paleography has come far in feature extraction, clustering, and visualization. But segmentation remains human-bound, a couture craft disguised as mechanical preprocessing. To “close the loop”—to move from semi-automated annotation to a genuine vision pipeline—is to let the system begin where I do: by noticing.
This, then, is the next frontier of APEX: dexterity to detection.
Teaching the Machine to See Like an Epigrapher
Overenthusiastic reading.
Underenthusiastic detection.
Segmentation is difficult not because machines are bad at vision, but because ancient writing is not meant for them. Lighting varies; stone gleams or shadows; lead reflects; letters fade into corrosion or merge in ligature. Scripts mutate, overlap, and misbehave. Non-Latin alphabets, especially, resist the tidy categories on which modern OCR depends. The machine expects Helvetica. What it gets is Styra.
Traditional OCR fails here because it assumes clean, printed forms—typographic regularity, not weathered intent. An epigrapher reads not just the mark but the gesture that made it. To approximate that sensitivity computationally is less about brute accuracy than about modeling discernment.
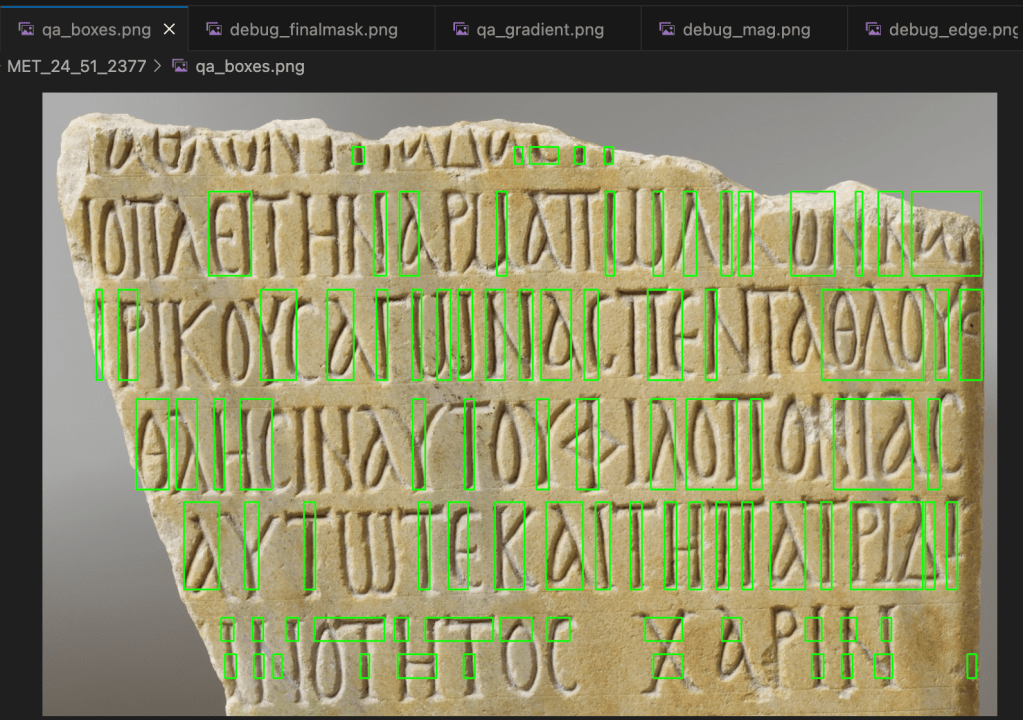
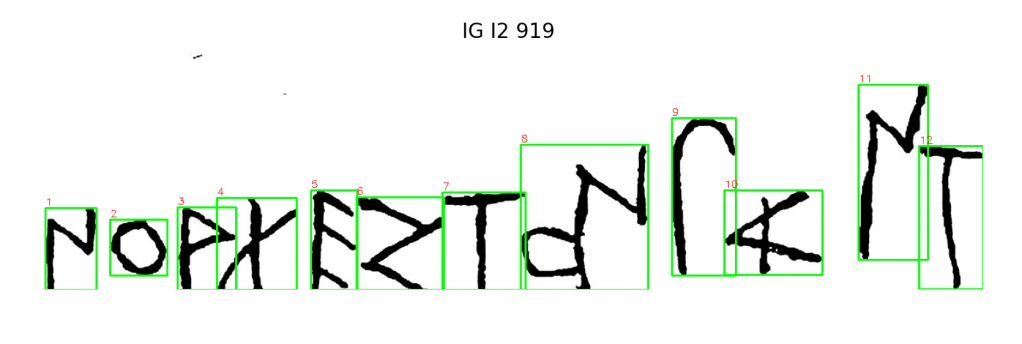
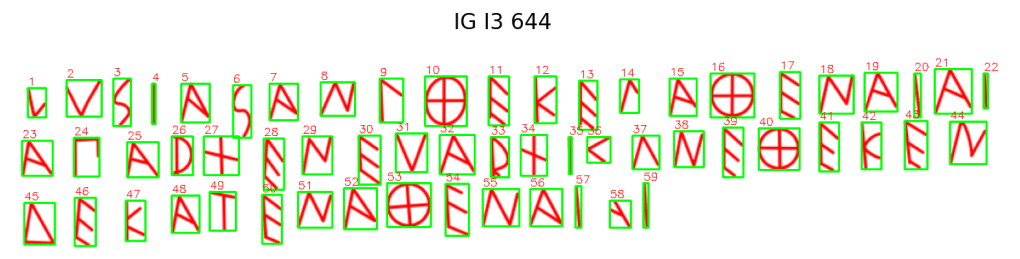
At present, APEX’s dataset contains roughly 2,000 glyphs across 50 inscription photos—each traced and annotated by hand. Those drawings are not just data; they are training material. They encode what human attention looks like when applied to ancient form.
The great tension ahead lies between fidelity and generalization: the need to preserve nuance while building a model that can scale. Building a dataset is a kind of digital fieldwork: slow, repetitive, and quietly devotional.
Getting closer, but still showing the limits of simply preprocessing and segmenting without ML.
Building Iteratively
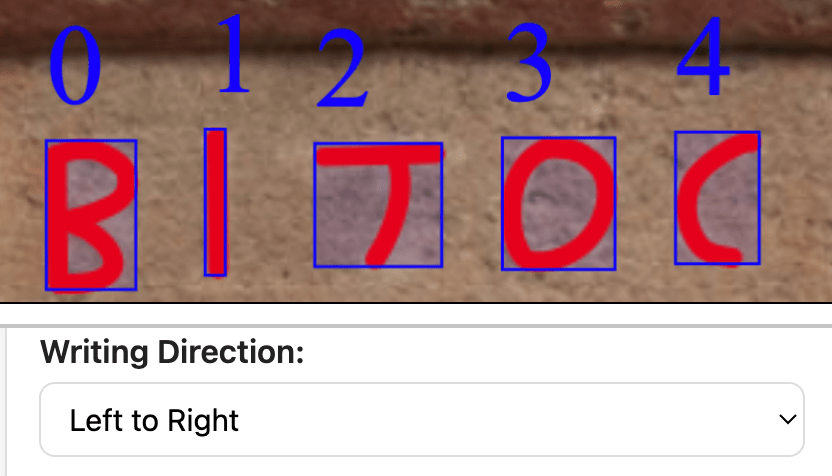
Phase 1 — Manual Baseline Create high-quality, human-annotated bounding boxes—each verified against the traced vectors. Establish a consistent schema: filenames, rights metadata, feature tables. This becomes the ground truth. Approximately 1/5 through my 10k glyph goal.
Phase 2 — Model Prototyping Train a small (YOLOv8 perhaps) segmentation model on the initial 2k glyphs. Evaluate precision and recall. Visualize false positives and negatives. Adjust preprocessing—normalize lighting, sharpen contrast, calibrate thresholds.
Phase 3 — Iterative Retraining Adopt a human-in-the-loop cycle. The model proposes and asks for clarifications; I correct and feed it the new data it needs in an active learning process. Those corrections return to the model as new training data. Each iteration, where I feed it 1k glyphs more at a time in targeted passes, improves both speed and fidelity.
Phase 4 — Integration with APEX Fold the trained segmenter into the APEX engine. Users will be able to run it locally or via API, generating structured, IIIF-ready outputs. The dashboard will visualize segmentation confidence and quality metrics in real time.
Phase 5 — Cross-Script Generalization Extend beyond Greek: Phoenician, Aramaic, Lydian, Coptic, and others. Develop shared feature ontologies for cross-script comparison. The horizon: a universal segmentation model for alphabetic writing.
What It Means to Eliminate a Bottleneck
To automate segmentation is not to replace the human but amplify what the human can attend to. The dream isn’t delegation but acceleration: letting the machine perform the gestures that would otherwise consume a lifetime, so that we can ask better questions.
The act of teaching a model to see is, in a way, an act of translation. Between disciplines, between forms of attention. APEX began as a bridge between ancient and digital worlds; this next stage extends that bridge into vision itself.
If segmentation is the bottleneck, then teaching the machine to see is the act of undamming the throat of the alphabet—to let the dead speak again, not in whispers, but in full computational voice.
Current GitHub repository structure. Detect layer to come.
As APEX has grown, its structure has become clearer. What began as 3 files—a single .html, .css, and .py each—in virtually continuous script (perhaps mirroring ancient inscriptions themselves) has developed into a layered system. Each part carries its own method and rhythm, but together form a complete research environment—a cycle that moves from inscription to dataset, from dataset to interpretation, and from interpretation to discovery.
The division is not hierarchical. Each layer depends on the others and stays in motion with them. Separating them made the system intelligible, something that can scale and adapt, something that can be thought inside of, with, and through.
0. Detect
APEX-detect is the system’s first act of perception, currently in development with a machine learning protocol. It won’t interpret or analyze; it’ll isolate. From the continuous surface of a photograph, it will identify the discrete marks that will later become glyphs. Detection turns light and texture into segmented boundaries, carving the visual field into fragments the Engine can later measure, compare, and encode.
1. Engine
APEX-engine is the analytical component. It extracts form from image, turning traced/detected letters into measurable geometry. This layer defines how APEX perceives the world of writing, translating shape into information that can be analyzed, compared, and preserved.
2. Database
APEX-db (public-facing name: AlphaBase) gathers what APEX-engine records. It stores inscriptions, glyphs, and metadata in a coherent schema that keeps the material legible across regions, languages, and media. Each entry carries its archaeological, linguistic, and graphical context. The database ensures continuity and keeps every trace.
3. Relate
The APEX-relate layer will give structure to connection. It is to join individual records into networks, revealing correspondences among letters, scripts, and regions. Relate will be the layer of inference, where data begins to show its meaning.
4. Find
APEX-find will make it all navigable, the memory and relations established by the previous two layers. It transforms the corpus into a searchable field, allowing queries by inscription, feature, script, or drawn form. Each result will draw on the underlying relational structure, turning the accumulated data into an accessible landscape. Find will be the gateway between APEX and its users, the point where the internal logic of the system meets the act of discovery.
5. Witness
APEX-behold is going to make the system visible to itself. It will render “on-premises” (as opposed to in external environments) the processes and relationships established by the other layers into sight: plots, maps, and visual fields where patterns take shape. The interface will allow the eye to follow what the model perceives, aligning computation with human attention.
The System as a Whole
These five layers create a loop of perception and understanding. The engine observes, the database retains, relate connects, find reveals, and witness visually consolidates. Each layer holds a distinct epistemology, shaping a system that can study writing as both artifact and behavior. APEX has reached a stage where its structure echoes its object of study: the layered evolution of form into meaning.
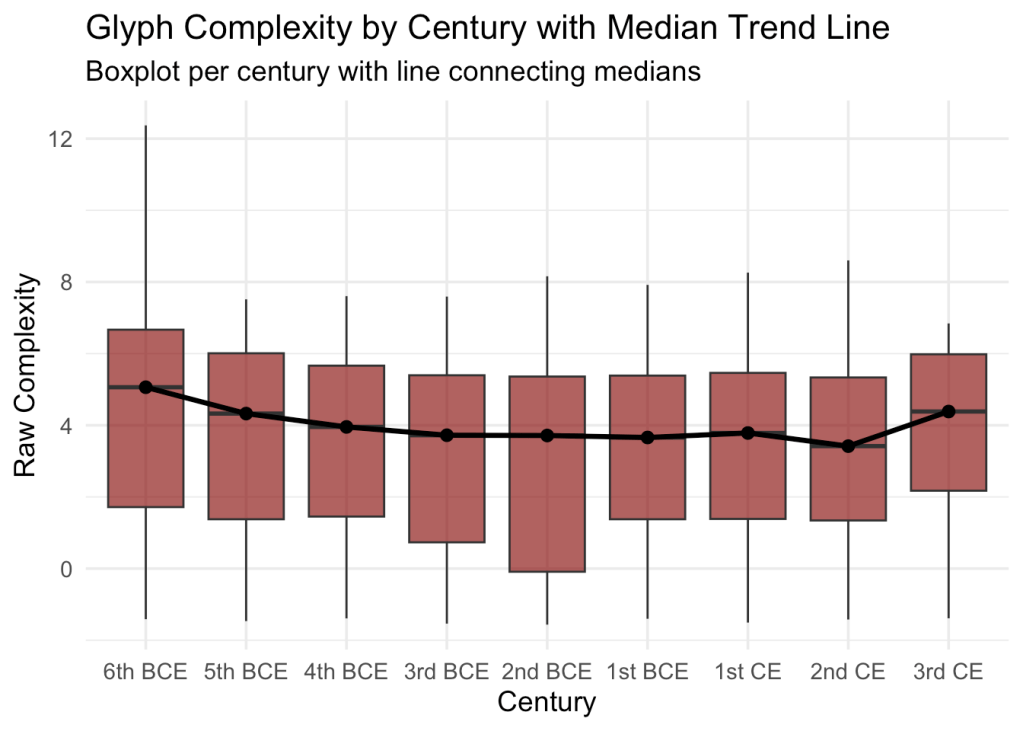
Complexity trends for three letters over 700 years on Euboea, from my forthcoming diachronic study.
When I began APEX seven months ago, I wrote that before theory comes tracing—the act of turning old strokes into structured data. Half a year later, that small act has grown into something larger: a functioning, extensible research environment capable of analyzing thousands of letterforms across hundreds of inscriptions.
If the last few months have been about proving the analytical potential of APEX, this one has been about deepening its usability—turning it from a powerful engine into a genuine workspace. The latest version, 1.9.1, focuses on the graphical user interface, which I only dreamed of last April. The idea was to give form to the human side of paleographemics: how scholars see, record, and reason through inscriptions.
The platform now balances two goals that usually pull in opposite directions. It is rigorous enough to handle multilingual, multi-directional corpora across millennia, yet flexible enough to capture interpretive uncertainty and scholarly disagreement.
1. The Corpus Grows
APEX now contains its first completed regional corpus: 209 lead curse tablets from 5th-century BCE Styra (Euboea), encompassing 1,857 individual glyphs, each manually traced, annotated, and analyzed through the full APEX pipeline. Alongside this is a parallel dataset of another 99 Euboean inscriptions, spanning roughly eight centuries—from the Archaic through the Hellenistic period—processed through an exploratory workflow still in development.
Together, these two datasets represent 4,990 glyphs from the island of Euboea alone, making this one of the largest and most detailed regional paleographic corpora currently in existence. This body of material allows APEX not only to test technical scalability but to examine a single region’s graphical traditions across a complete chronological arc.
Selected gallery of “Most Typical Glyphs by Letter” from Styra lead tablet report.
Within Styra alone, clear structural tendencies emerge. Across the 1,857 analyzed glyphs, symmetry and complexity show a strong inverse relationship, as expected, but now quantified. Others—especially theta and, unexpectedly, many iotas—deviate, showing that simplicity and circularity were not universal ideals but locally negotiated habits.
Classical intuitions—decreasing complexity through the Archaic and Early Classical periods, a plateau, then a late stylistic uptick—are confirmed here, but more importantly, they’re now quantified
Across the broader eight-century span, early tendencies toward angularity give way to smoother, more balanced forms. Though not universally—delta stands out, evolving from a 2-stroke rounded D-shape to the familiar 3-stroke angular Δ, a shift that mirrors the broader transition from ductus-driven to design-driven writing. Nonetheless, this broadly confirmed long-standing epigraphic intuitions, but for the first time, making them concrete and measurable.
Taken together, the data suggest that what epigraphers once described qualitatively as a “balanced hand” or “tidy style” can now be measured as a structural principle—evidence that writers (whoever they may be, trained scribes or so-called ordinary people) in 5th-century Styra pursued an underlying visual economy that blurred the boundary between mechanical habit and aesthetic intention.
2. The Interface Takes Shape
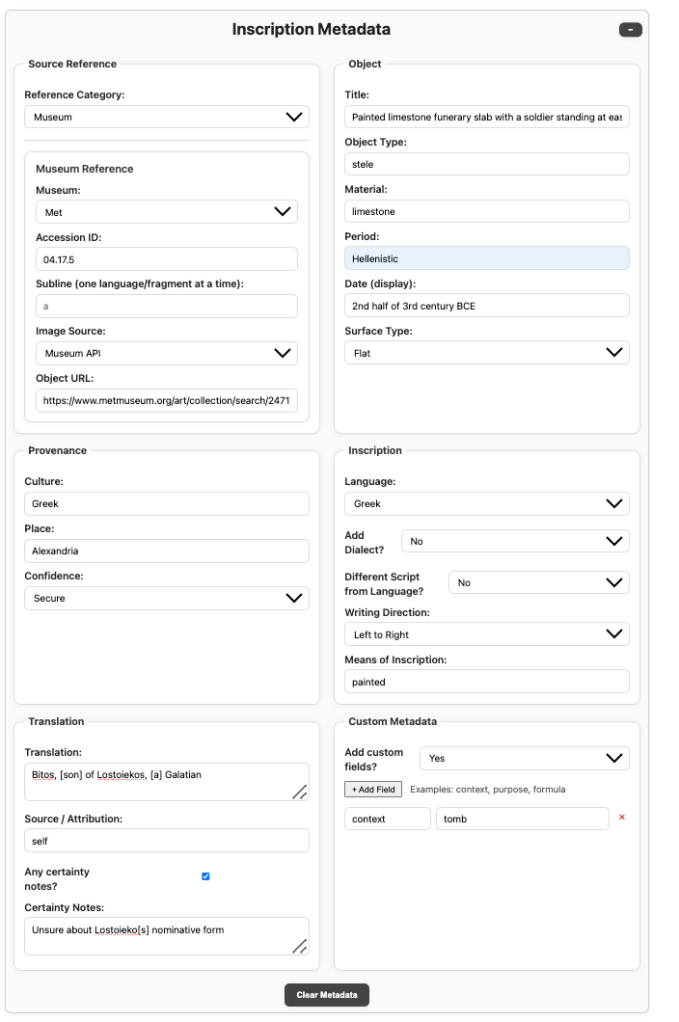
v1.9.1 particularly hinges on a comprehensive Inscription Metadata panel—a modular framework for recording everything an inscription can tell us: provenance, language, writing direction, translation, confidence, and context.
The (very granular) metadata panel, designed for maximum precision. This will later allow highly dimensional, unsupervised machine learning (ML) to be performed.
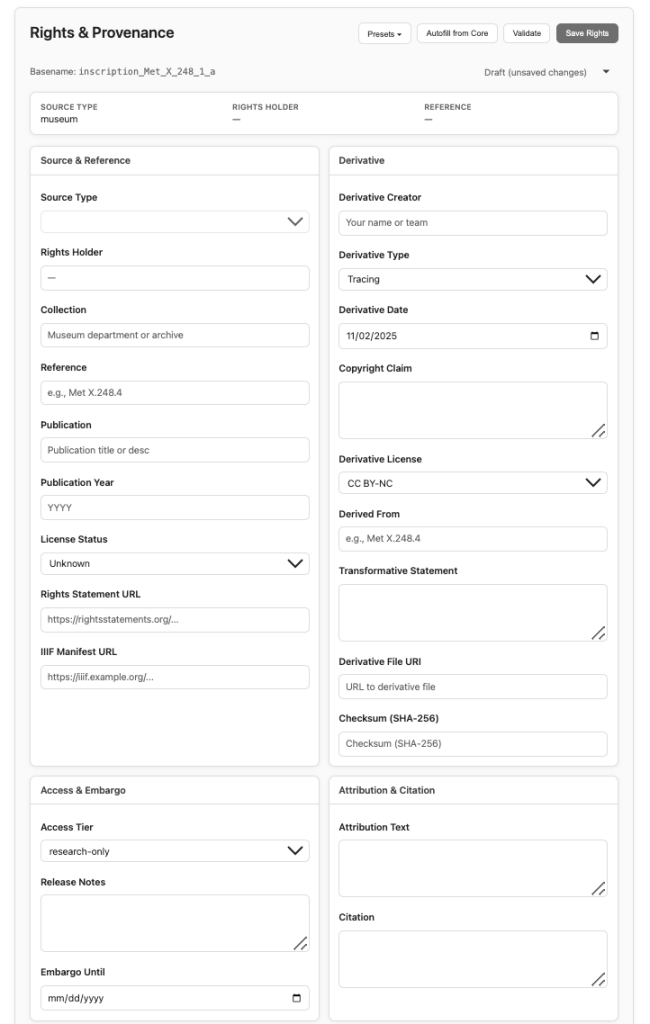
Furthermore, there’s an extensive rights and permissions panel just below that. This enables future rights-safe integration with public databases, preserving sensitive and restricted information from accidental reproduction—critical in heritage preservation and in preventing looting/destruction, especially in conflict zones. Now that I’m pivoting to working with data outside of the public domain, this is a non-negotiable feature, and I hope this is a practice that others replicate when fusing rights-diverse corpora. Below is the model of that.
Each record can now be broken into sublines, allowing users to specify separate languages and writing directions within a single inscription. This makes it possible to manually encode boustrophedon layouts, alternating left-to-right and right-to-left lines without losing reading order. The same applies for multilingual inscriptions: the user isolates each portion of a different language subline to analyze individually. However, true schlangenschrift—the serpentine style of continuous directional change—remains a technical frontier still ahead, but the architecture for handling it is now in place.
For a Greek inscripion.For an Aramaic inscription.
Bounding boxes are direction-aware, indexed according to reading orientation, ensuring that extracted visual features align correctly with the direction of writing. Metadata imports from museum APIs are now supported, and flexible fields allow users to enter additional descriptors such as inscription purpose, formula, or archaeological context.
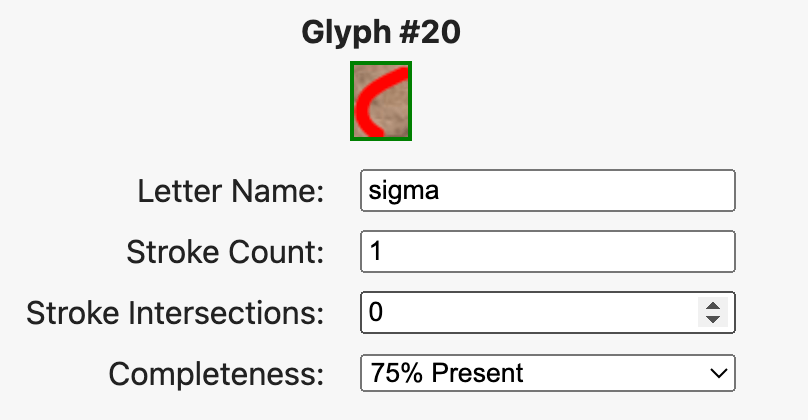
3. Encoding the Human Element
Each glyph now carries its own metadata through a compact per-glyph panel. Users can record completeness, stroke count, and intersection data, and—critically—can flag alternative readings where forms are contested. The new Scholarship Mode attributes alternate identifications to specific scholars or corpora, creating a visible interpretive genealogy and turning disagreement into structured data.
5-tier completeness flags now present.
What results is a layered model of knowledge. APEX no longer treats the epigrapher’s uncertainty as noise; it considers it data. Each recorded disagreement becomes part of the historical record of how these inscriptions have been read.
User can now cite alternative readings and the reasoning for them.
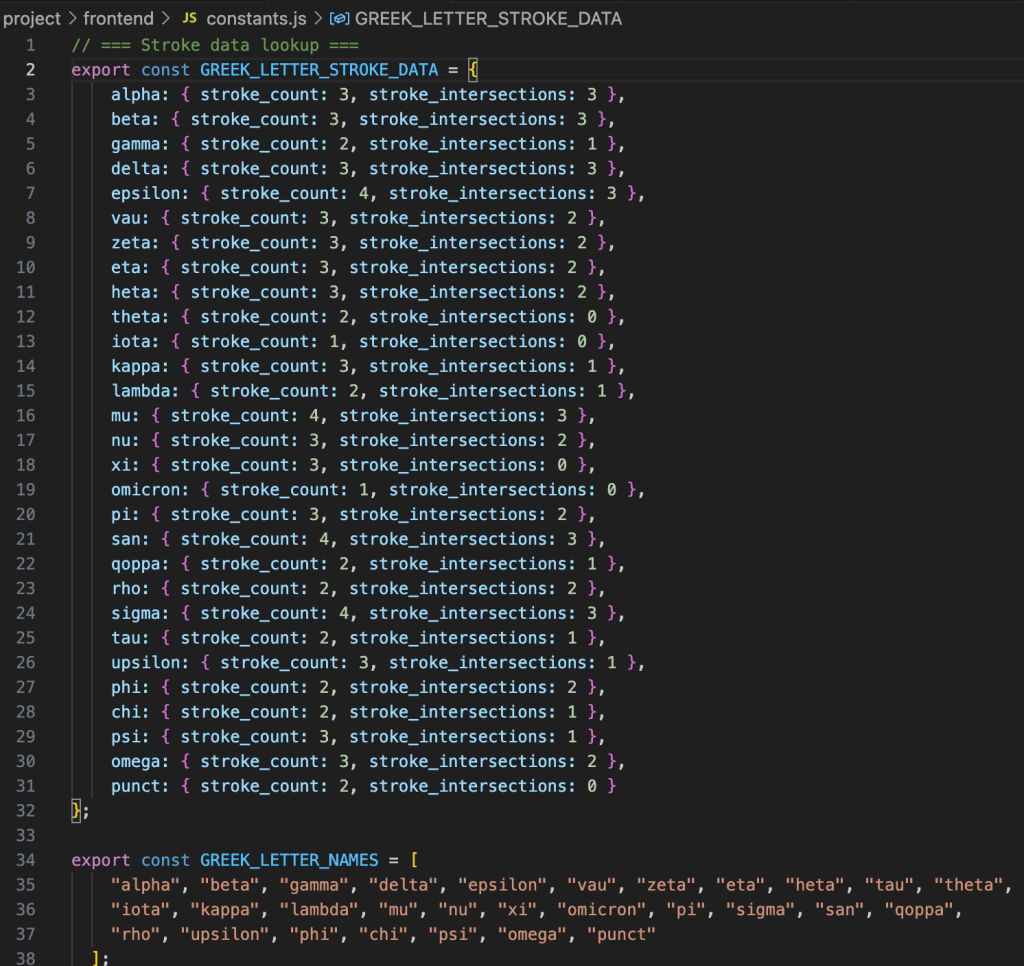
4. Intelligent Defaults
Five editable, language-aware dictionaries now exist for the GCELL script cluster, i.e., Greek, Coptic, Etruscan, Latin, and Lydian. There are another five dictionaries on the way for the PASHA branch: Phoenician, Aramaic, Semitic, Hebrew, and Arabian. This capability autofills letter names with their expected stroke and intersection counts, cutting per-glyph processing time by ~70%. These default expectations provide baselines for feature extraction and make visible the subtle divergences that define local or experimental hands.
The dynamic Greek dictionary.
5. From Interface to Insight
The combination of robust metadata, per-glyph fields, and structured dictionaries has turned APEX into a living research environment. A researcher can now import an object from a museum API, record multilingual metadata, define directionality, tag individual glyphs, and export a ready-to-analyze JSON file—all within a single interface.
Early exploratory notebooks using the full eight-century dataset are already visualizing regional drift and stylistic convergence over time. Though not yet publishable, these models provide a first view of how letterforms move within and between centuries, forming clusters of continuity and outliers of innovation.
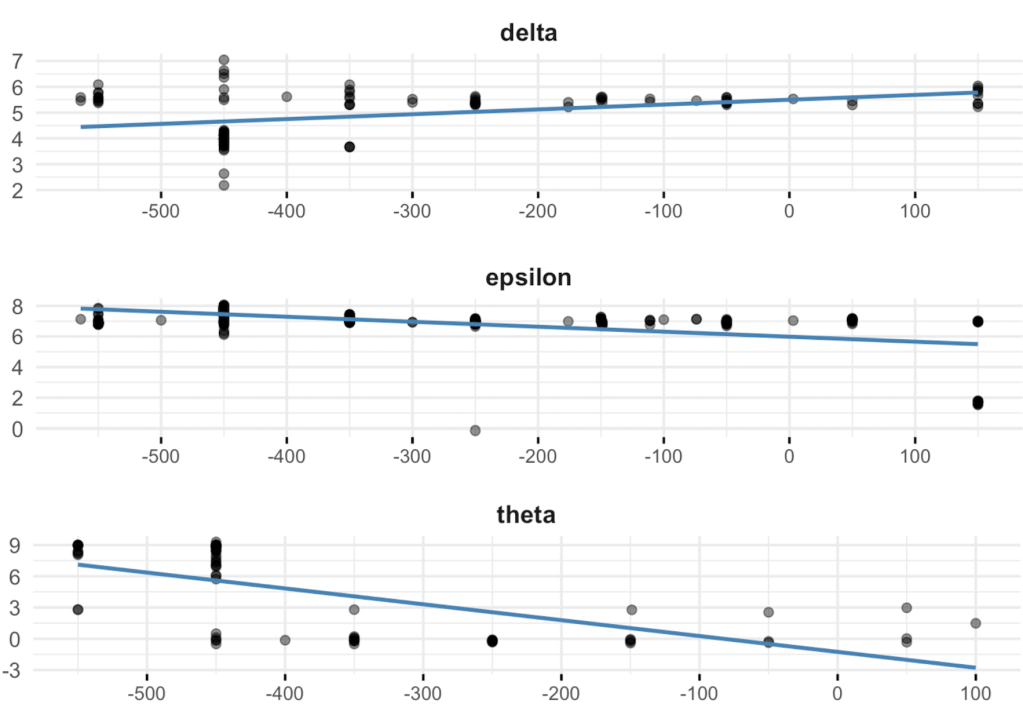
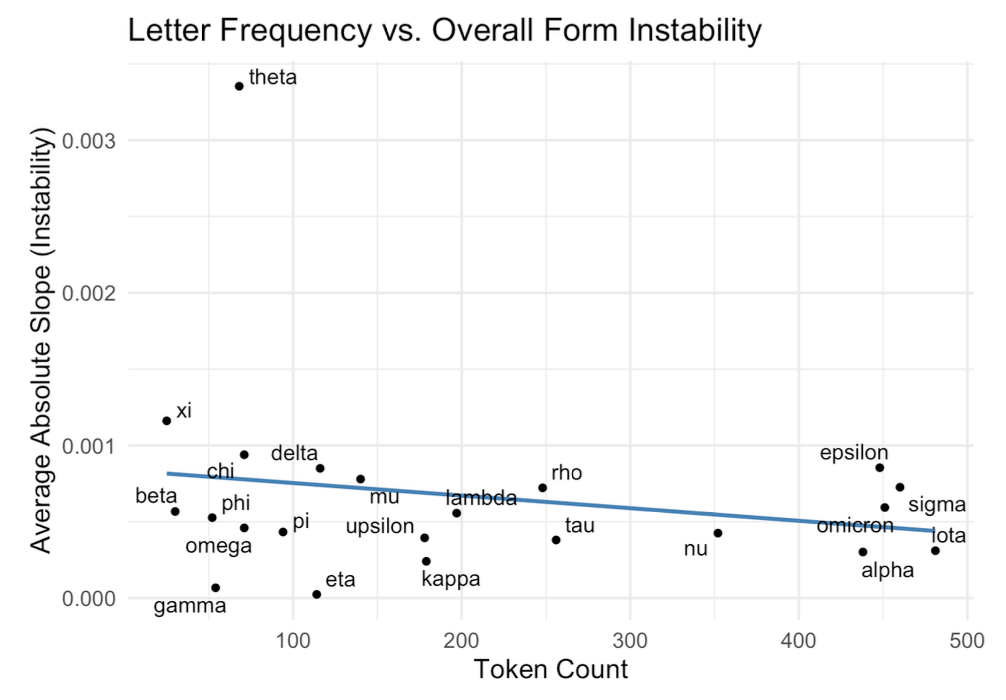
Critically, they also provide examples contrary to certain received wisdom. See the following chart, and note that the p-value of this correlation is p = 0.37, well above the <0.05 threshold for statistical significance in the social sciences.
In the eight-century dataset, letter frequency shows only a weak and statistically insignificant relationship to graphical stability. The trend line slopes slightly downward—more common letters like alpha, sigma, and omicron are somewhat more stable—but the effect is far from reliable. This suggests that the conventional linguistic expectation—that frequently used units remain more conservative—does not translate cleanly to letterforms. Here, stability may follow style and medium more than frequency.
6. Reflection
The major achievement of this phase is not simply scale—it’s integration. APEX has reached a point where drawing, data entry, and interpretation form a continuous loop. Each inscription is both a record of ancient writing and a record of modern reading.
With nearly five thousand glyphs from one major region already processed, APEX is beginning to reveal what paleographemics promises: the ability to study writing as a cultural system that can be seen, measured, and compared without losing its human texture.
Back in February, I thought two months was enough time to date the transmission of the Greek alphabet.
That was my starting point: a delusional hope. And indeed I began APEX with scant technical ability—poor grasp of concepts and a month of coding background—just a sense that there was something doable at the intersection of computational method and ancient script. That if I could just find a way to measure the shapes of letters, I might be able to tell a new kind of story about how the alphabet traveled, evolved, settled into forms.
It turns out: no, I can’t date the transmission of the alphabet, not at 21, not in 10 weeks. But what I can do is more interesting than I could’ve imagined.
The first time my bounding boxes returned in the correct order, it felt like a miracle. Then came the multiline inscriptions, then symmetry, then even raw drawings, not traced. Every breakthrough brought a little more light. Eventually I wasn’t just copying, being derivative—I was quantifying, contributing. My complexity metric sharpened. The overlay lines grew more reliable. And like a planet in formation, the project developed a center of gravity—and it began to cohere.
And I encountered some surprises, as in the section “Dipylon: When the Data Doesn’t Flinch.” A particular early inscription came back less complex than many of the later ones I tested. That result challenged not just my expectations, but my entire premise. It forced me to reckon with how many qualitative judgments still underpin every “quantitative” metric I generate. What counts as complexity? What gets weighted, and why? Those choices are human. They’re mine.
That’s the most important thing I’ve learned: you don’t escape interpretation by adding math. You just make the interpretation a little more legible. Hopefully.
But still: I measured something. I made a system that can trace chaos and extract structure—not to flatten but honor. The alphabet, in its earliest known Greek forms, is no longer just a field of intuition or artistry or tradition. It’s data. It’s patterns. It’s beautiful.
What does this moment feel like? It feels like I just landed a man on the moon, as in that grainy black-and-white footage: men in short-sleeved white shirts and skinny ties, erupting with joy when the impossible became real. That’s me right now—except I’m just an undergrad with an old laptop and the stubborn belief that I can make something for the field I love.
After months of tracing, testing, and theorizing, APEX just did something real. AlphaBase is expanding. This is what it felt like to land the letters.
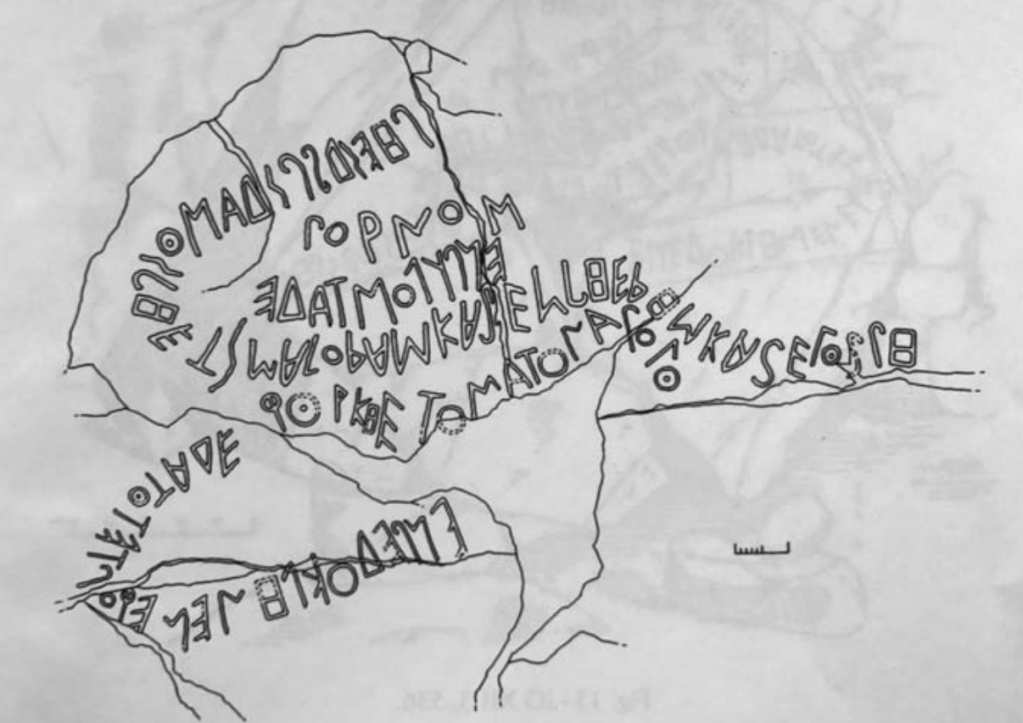
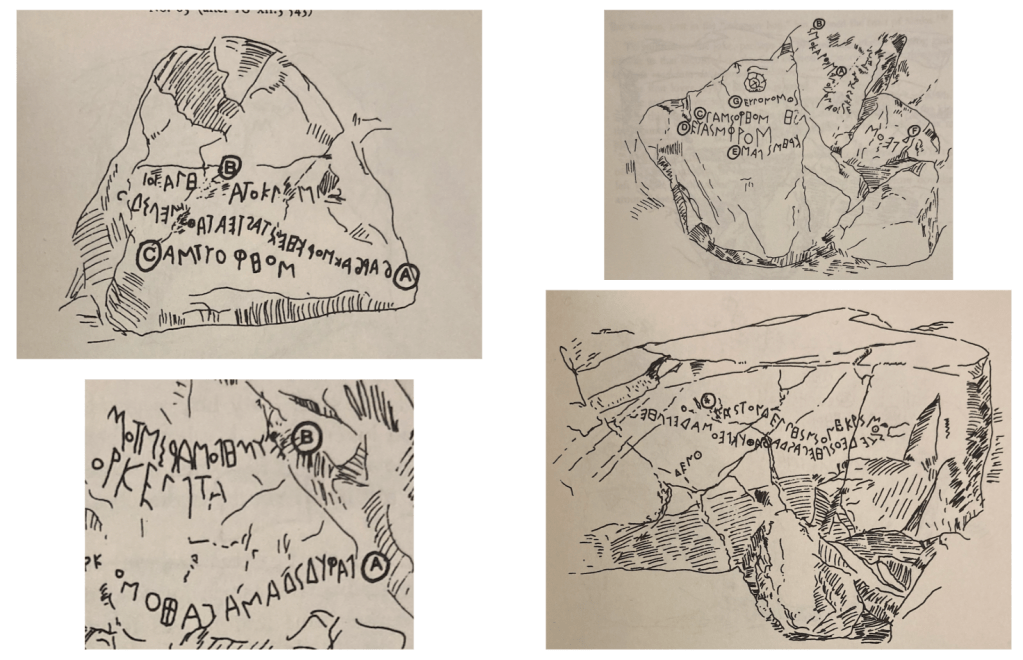
A “snaking” inscription: IG XII 3.536, from Inglese (2008), ISBN-13: 9788888617138.
Every interface encodes assumptions, whether on the level of metadata or internal features. Most modern text annotation tools—whether for OCR, NLP, or digital paleography—assume that text runs left to right (dextrograde), top to bottom, in straight lines. Even tools designed for right-to-left (sinistrograde) scripts or vertical layouts often presume uniform orientation and stable reading order. But the moment you encounter Schlangenschrift (examples here and here), or even boustrophedon, (below) that all breaks down.
Schlangenschrift, German for “snake writing,” is the term for inscriptions that undulate, loop, or zigzag across their surfaces. They aren’t just retrograde or boustrophedon—they’re playful, nonlinear, and sometimes aggressively nonstandard. Letters may rotate far off baseline, reverse, snake along the rim of a vessel, or float in clustered spirals. They don’t just stretch orthographic conventions—they revel in their own performative visuality.
That’s thrilling, but let me tell you, it’s a pain to encode.
What Makes Schlangenschrift Hard to Handle?
In traditional inscriptions, we assume a stable direction of writing and an inferred reading order from layout. Schlangenschrift breaks both assumptions. Letters might be inverted, flipped, or rotated 180°, and their spatial arrangement doesn’t always match their intended sequence.
This poses problems for annotation on two levels:
How do you tell the system that a letter halfway down the curve should be read before the one at the top?
How do you capture the fact that an archaic alpha is legible but flipped, or that an theta has been rotated 100° clockwise?
And this is before we even deal with issues like ligatures, joined strokes, or unclear boundaries between clustered forms.
What I need eventually is a dedicated GUI: a tool that allows me to annotate forms visually, directly on the letter or inscription image, and store that information in a structured, model-readable format. A few things I imagine it allowing me to do:
Adjust or override reading order by selecting letters in intended sequence
Tag rotation by clicking the “top” of a letter (especially useful for characters rotated more than 90° off baseline)
Split ligatures or joined forms into discrete units—or possibly annotate them as double-readings when appropriate
Attach manual labels and feature flags that will eventually train an ML model to handle the first-pass extraction
In other words, it’s to be a tool that lets human judgment scaffold machine learning—not the other way around. I also hope for it to be accessible to scholars uploading and annotating other inscriptions down the line. After all, it’s called the Alphabetic Paleo-Epigraphic Exchange, and from the beginning it’s been my vision to build a diverse, international, and collaborative community.
Design for a Script That Doesn’t Behave
This GUI wouldn’t be a general-purpose annotation tool, at least, not yet. Perhaps its scope could be expanded if comparative script capabilities (cf. Stages 4 and 5) are added. However, for now, it’ll be shaped by the idiosyncrasies of Greek epigraphy, and especially by the freedom and experimentation of the Archaic period. It would let me preserve uncertainty and flag ambiguity. It would let me document weirdness rather than flatten it.
It might also include inscription-level features: recording whether the script is sinistrograde, boustrophedon, or Schlangenschrift; marking axis drift; allowing toggling between epichoric and normalized readings.
Eventually, I’d like to use this tool not just for Schlangenschrift but for all complex inscriptions—especially ones where reading direction, orientation, and letter identity are uncertain or debated.
For now, though, this post is part wishlist, part blueprint. If you’ve worked on annotation tools for nonlinear writing systems—or have thoughts about how to handle radical variation in letter layout—I’d love to hear from you: tfavdw@nyu.edu.
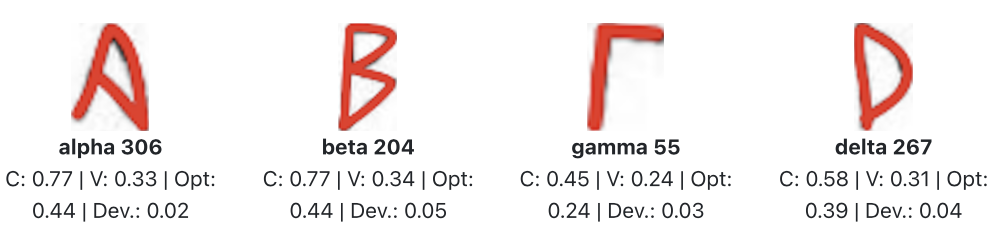
The twelve most complex glyphs in the Styra lead tablet dataset—all thetas. “C” denotes calculated complexity; “V” indicates vertical symmetry. For more context, see the abridged Styra dataset report.This gallery excludes thetas to give a fuller picture of complexity in the Styra cache.
If symmetry was the most natural place to begin—clean, measurable, culturally resonant—then complexity is where things get thornier. This post is about defining and quantifying visual complexity in early Greek letterforms, and why it matters for understanding both the mechanics and the aesthetics of the alphabet’s evolution.
Why Complexity?
Symmetry tells us how aligned a letterform is to itself. Complexity, by contrast, captures how much is going on—how many strokes, how much intersection, the degree of irregularity. Where symmetry can often be intuited at a glance, complexity resists easy perception—but it may prove just as revealing.
I’m interested in complexity as I suspect it plays a major role in the process of visual regularization. If the transmission of the Greek alphabet involved adaptation and simplification, as many have proposed, then more complex letterforms might point toward earlier or more conservative stages. In other cases, complexity might reflect local experimentation or ornamental flair. Either way, tracking it diachronically and geographically could tell us when and where scribes began to standardize—or drift.
How I’m Defining It (For Now)
Unlike symmetry, which can be modeled with relatively stable geometric principles, complexity requires interpretive decisions. For now, I’m treating it as a composite score, derived from features already being measured in APEX. My provisional formula looks like this:
+ (0.5)Stroke_Count + (0.5)Stroke_Intersections
– (0.2)Curvature – (0.2)Symmetry [composed of reflectional and rotational].
In short: more strokes and intersections add complexity, while curvature and symmetry reduce it. Each term is then normalized on a 0–1 scale.
I’m also considering adding a term for relative stroke length, to account for letters that are not just busy but expansive.
Likewise, I’m thinking about adding script direction: if boustrophedon or Schlangenschrift, that adds some complexity too; perhaps adding .5 for the former and 1 for the latter; however, this is an inscription-level feature rather than letter-level. Perhaps I have a separate complexity feature for the overall inscription, including things like average orientation, internal orientation consistency, and internal letter consistency.
Note: this is emphatically a first draft. The weights are intuitive rather than statistically derived, and the model doesn’t yet differentiate between necessary complexity (as in psi or early mu) and anomalous embellishment. Still, it gives me a way to compare letters on a rough scale—from clean and minimal to dense and ornate. I’m also fortunately free of having to account for degree of serif, as this emerges much later and so is outside of my scope (at least for now), and I get the sense a computer would struggle to measure that feature.
If you have any ideas or input please email me at tfavdw@nyu.edu! I’d love to hear from readers on this.
The Value of a Secondary Feature
Complexity is a secondary analysis within APEX. It draws on multiple primary measurements (stroke count, symmetry, curvature, etc.), and as such, it’s vulnerable to all the noise and ambiguity in those inputs. But it also offers a different kind of power: it’s a synthetic trait, one that may correlate with regional style, inscription context, material, date, or internal regularity.
Some questions I’m exploring through this lens:
Do earlier inscriptions have higher average complexity?
Are some regions more tolerant of complexity than others?
Which places and periods hew more closely to Phoenician models? Similar complexity scores between Greek and Phoenician forms may offer a useful proxy for scribal conservatism.
Does higher complexity correlate with less consistency within a single inscription?
Are certain materials (pottery, stone, lead) more prone to complex forms?
Eventually, I’d like to correlate complexity with features like orientation consistency, inter-letter spacing, and standardization level—some of which are already outlined in the APEX coding manual.
The Bigger Picture
If symmetry is about balance, complexity is about density, constraint, and the friction between tradition and invention. My goal isn’t to reward simplicity or penalize elaboration—it’s to understand what these features meant, when they appeared, and how they were shaped by the scribes who carved them.
The evolution of our alphabet over the past ~3750 years. Note that symmetry only seems to increase, with only 7 of 26 characters not exhibiting either full or apparent symmetry. Note: I’m counting N and Z as “apparently symmetrical,” giving us 7 of 26 (27%) asymmetricals, a significantly lower amount than the 9 of 22 in Sinaitic (41%) and 10 of 26 (38%) in Archaic Greek.
Before I can ask anything ambitious of my data—like modeling transmission pathways or quantifying regional scribal variation—I have to start with something smaller, simpler, and more grounded. For APEX, that starting point is symmetry.
Symmetry is one of the most visible differences between early Greek and Phoenician scripts. Even without training, most observers can sense the change: Greek letterforms become cleaner, more aligned, more balanced. But to measure that symmetry, I’ve had to define what I mean by symmetry, and build a method to detect it.
This post outlines how I’m operationalizing symmetry in the APEX corpus, why it’s the first feature I’ve chosen to model, and what it’s teaching me about the limits and affordances of computational paleography.
What Symmetry Means Here
In APEX, symmetry is a composite of two measurable traits:
Reflectional: How closely a letter matches its own mirror image, along the axis that yields the best fit—whether vertical, horizontal, diagonal, or something in between.
Rotational: How closely the letter approximates balance when rotated around a central point—typically 180°, though full radial symmetry is rare.
Each of these metrics contributes to an overall symmetry score, though I haven’t yet decided how to weight them relative to each other. (Letters like omicron may score high on both; others like early mu—the one that looks a bit like a waving flag—might have almost none.) The flexibility in axis choice is essential: a rigid expectation of vertical or horizontal mirroring would misread the creative variability of early inscriptions.
Why Symmetry First?
I chose symmetry as APEX’s first feature not because it’s easy, but because it’s easier—more tractable and revealing than most other options on the table. Here’s why:
Symmetry can be formalized geometrically and scored algorithmically, whereas features like curvature or stroke order require more interpretive preprocessing.
It aligns closely with what I called the Geometric Mindset in APEX 5. The Greeks didn’t just write more symmetrically—they seemed to want symmetry. Modeling this desire helps us understand the aesthetics of early alphabetic culture.
Because symmetry is something humans are so good at perceiving, I can use qualitative intuition as a check on the model’s output. If my code says chi is less symmetric than theta, that better match what I see—or I’ll need to refine the metric.
Most importantly, symmetry provides a rigorous baseline. If APEX can measure it reliably, I’ll have a working pipeline to test more complex or subtle features.
How I’m Measuring It
Reflectional symmetry is assessed by identifying the axis of symmetry that produces the highest match between a letter and its mirror. I use a series of transformations—rotation, scaling, and reflection—to find the optimal axis, then measure the residual difference between the original and the reflected form.
Rotational symmetry is calculated by rotating the letter around its centroid and comparing the rotated image with the original. This is usually done in 180° increments, though future iterations may allow for more granular angular measurements.
These outputs will be normalized and combined into a single score. I haven’t yet established weighting, since the balance between reflectional and rotational symmetry might vary by letter category or epigraphic tradition.
The Limits of Automation (So Far)
My computer vision pipeline still has limits. I’m developing this in Python, though most of my coding experience until now has been in R and Java. Here’s what’s working—and what’s not:
My current process overcounts contours by a factor of several hundred, especially in letters with nested or fragmented strokes.
It struggles to distinguish meaningful intersections (like the vertex of alpha) from noise, since it doesn’t yet recognize stroke logic.
Stroke direction is currently inaccessible: I’d need to first solve stroke segmentation, possibly via a trained ML model.
Curvature is hard to measure when the program doesn’t know how many strokes it’s looking at.
Symmetry, for now, is the best foothold: visually salient, structurally clean, and relatively resistant to contour noise—especially when preprocessing is done carefully.
From Obvious Insight to Quantified Claim
Everyone who looks at early Greek inscriptions notices the symmetry. What APEX is trying to do is not discover that fact, but confirm it rigorously—to move from impression to measurement, from observation to score.
This quantification isn’t the end goal. It’s the start of a methodology that can be applied to more difficult questions: which regions favor symmetry more, and when? How do letterforms regularize over time? Does high symmetry correlate with other features—like vertical alignment, spacing, or axis orientation?
Before symmetry became a measurable feature, it was a feeling—one the early Greek world seems deeply attuned to. This post is about that feeling: the cultural, aesthetic, and even spiritual logic that helped shape the forms of the first Greek letters. I call it the Geometric Mindset, a theory I presented to an NYU classics organization—you can find those slides here. (Note: This presentation is image-heavy; I’ve included speaker notes for clarity.)
Essentially, I believe the Greeks’ existing material culture had so thoroughly absorbed geometrism across media that they were primed to favor symmetry, regularity, and visual order—even in a new medium like writing. These features emerged after a period of exploratory and often whimsical experimentation in the Early Archaic. Dates and historiography of this period vary, but it lasts from approximately 750 to 600 BCE.
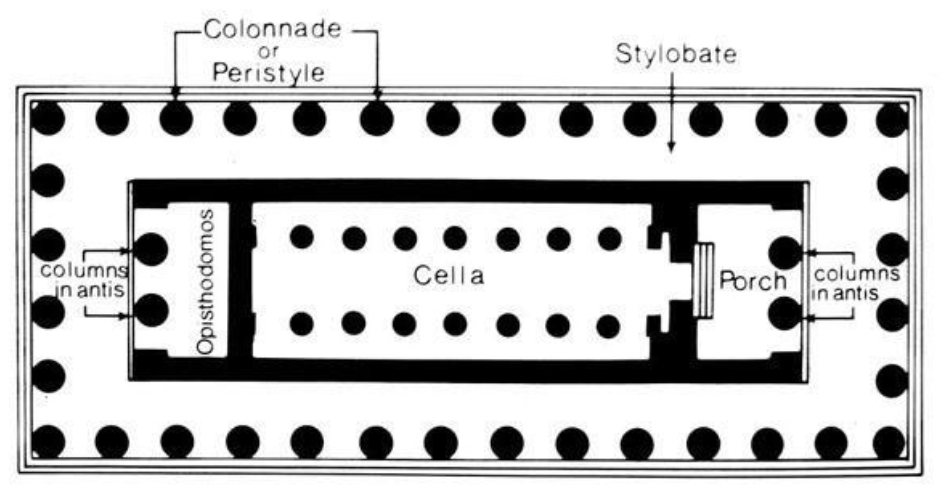
This geometric mindset is hard to define but easy to see. Look at a pot from the Late Geometric period—ending c. 760 BCE—and you’ll find meanders, triangles, and radial bands, repeated with a kind of cosmic insistence. Look at the floorplan of an early temple, and you’ll find axial balance and rhythmic repetition. Look at a letter like omicron carved around this time—round, even, self-contained—and you start to sense a common visual logic. In a world recovering from the Late Bronze Age collapse (c. 1177 BCE), symmetry didn’t just “look good”: it symbolized an order that people lacked and longed for.
Geometrism Before the Alphabet
After the Mycenaean palatial system collapsed around 1177 BCE, Greek society fragmented. Writing disappeared, monumental architecture vanished, and prestige grave goods diminished. In this post-palatial vacuum, the Geometric period emerged—not as a conscious revival, but as a new cultural orientation toward precision, repetition, and stability.
Art historians have long noted the stark transition: from figural representation to geometric abstraction. Between 900–850 BCE, human forms vanish almost entirely from the artistic record. When they reappear, it is only as stylized silhouettes built from circles and triangles. Architecture follows suit: the earliest Greek temples (many in perishable materials) were already laid out in balanced, rectilinear plans that would later be canonized in Doric and Ionic orders. Even the decorative motifs on grave pots shift from curvilinear swirls to angular meanders.
Plan of an Archaic temple. Note the high degree of symmetry and order.
A Canonical Doric scheme.
Technological changes—like the fast-spinning potter’s wheel or rectilinear timber—helped enable this aesthetic, but they can’t explain its pervasiveness. The geometric shift wasn’t just a byproduct of tools. It was a cultural choice.
Sacred Letters, Sacred Shapes
Phylogenetic tree of the Greek alphabet.
The Greek alphabet appears during this same geometric moment. And while it was adapted from Phoenician, the changes made were not purely phonological. They were visual. Symmetry increases. Stroke lengths even out. Letters gain internal alignment. In some cases—like theta or chi—they become almost iconic of the aesthetic that surrounds them.
The two earliest known Greek inscriptions, both in verse. 1: Nestor’s Cup, Pithekoussai colonty (Ischia, in modern Italy). 2: Dipylon Inscription, Athens.
Why? Part of the answer lies in the way writing was first received. Unlike every other writing tradition in the world, there is no evidence the system first emerged for economic or administrative purposes. Rather, the earliest alphabetic Greek inscriptions are not inventories or contracts but poems, hymns, names, and dedicatory verses (verses!) to the gods. Writing in early Greece was not merely functional—it was mystical. In the early abecedaries offered at sanctuaries like Mt. Hymettos, the alphabet itself appears as a sacred object. Its form mattered.
Abecedaries (an inscription where an alphabet is written out, rather than having lexical meaning) and fragments thereof found in sacred Greek and Etruscan contexts.
Early attitudes of letterform as artistic motif are also exhibited in the inscriptions left by people at the margins of literate society: shepherds in Attica, young men on Thera (modern Santorini). Their graffiti mixes geometric regularity with expressive play. Letters are art, snaking across stone in “Schlangenschrift,” reversing and rotating in boustrophedon—they stretch, compress, and play. These are not yet standardized forms—but they are already aesthetic ones.
The Theran Schlangenschrift inscriptions.Examples of Attic shepherd graffiti.
Writing, like poetry, was a medium of presence. To inscribe a name was to fix it. To make it visible. To give it shape. And that shape, increasingly, was geometric—according with the idea that the Greeks were in some way primed by their existing architecture, material culture, and general sense of the aesthetic.
Importance to APEX
APEX isn’t just a computational project—it’s a cultural one. Before I try to model formal features, I need to understand what counted as a “good” or “complete” letter to the people who made them. The Geometric Mindset gives me a crucial frame. It tells me that the first Greek inscriptions weren’t striving for speed or utility—they were striving for balance.
That’s why the first feature APEX will try to model is symmetry, as covered in APEX Updates, 6. Because it’s not just a trait but a trace—an artifact of a whole worldview. In the next post, I’ll explain how I’m operationalizing part of that concept: how I define and measure symmetry, and what the limits of those measurements tell us about what the Greeks may have seen and wanted in a letter. To measure symmetry, then, is not to quantify a style—it’s to reconstruct a logic, a way of seeing, and a schematic of belief.

















{kind=link}
{kind=link}