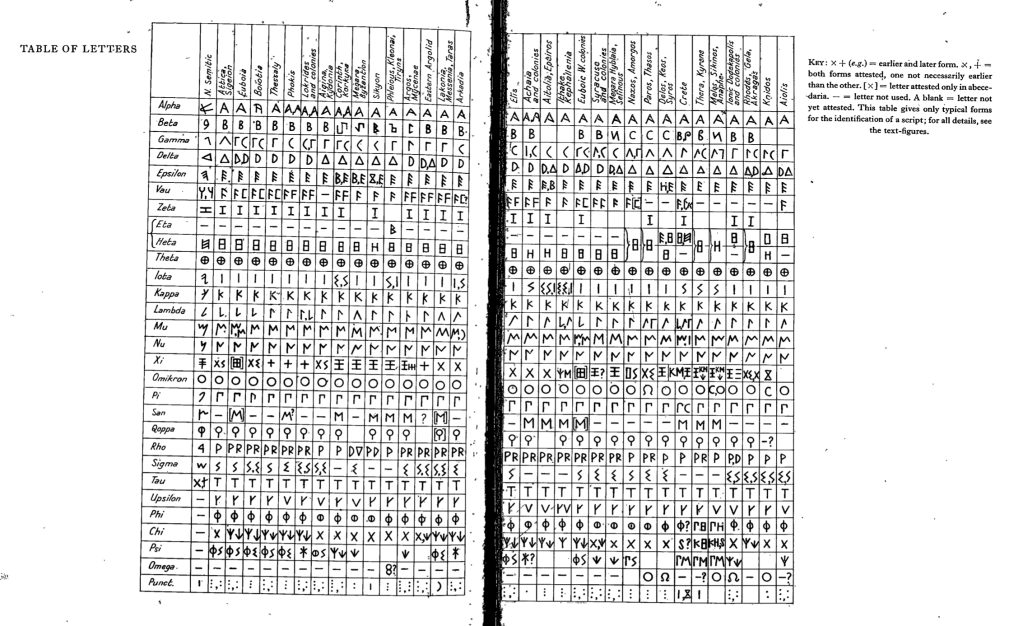
It is foundational for any work on early regional Greek scripts.
There are very few books I consider truly irreplaceable in my research. Lilian H. Jeffery’s The Local Scripts of Archaic Greece is one of them. First published in 1961 and revised in 1990 with A.W. Johnston, this book remains the reference for regional variations in the Greek alphabet during the archaic period. It’s where I first learned to read epichoric inscriptions with the eye of a paleographer rather than a Classicist alone.
The book is very hard to find, and I only got my copy at an even remotely affordable price after months of scouring secondhand sellers. While copies still circulate among libraries and the used book market, I wanted to make it more accessible to others working in this area. So I hunted diligently before finding it on the Internet Archive. You can read or download it here:
The Local Scripts of Archaic Greece (1990 ed.) – Internet Archive
Jeffery’s study remains foundational for any work on early Greek writing—not just in Athens or Ionia, but across the full spectrum of regional scripts: Corinthian, Euboian, Attic-Boeotian, Cretan, Cycladic, and others. It includes extensive commentary, maps, and an invaluable inscriptional catalogue organized by region, with drawings and typographic transcriptions. The 1990 revision added important corrections, expanded references, and additional illustrative material. For those of us studying alphabetic transmission, especially the Phoenician-Greek interface or the evolution of letterforms over time, this book is indispensable.
What makes Local Scripts especially useful is that it bridges the gap between paleography, archaeology, and linguistics. Jeffery doesn’t just chart when and where a particular variant of alpha or epsilon shows up—she explains what those variations might imply for chronology, influence, and contact. And although her typology has been revised and challenged in places (especially with the discovery of new inscriptions), her system remains a critical baseline for almost every study that’s come after.
Whether you’re interested in early Greek literacy, the transmission of the alphabet, the sociopolitical meaning of epigraphy, or just want to be able to tell the difference between Laconian and Euboian chi, this is the book to start with. I hope having it freely available will be helpful to others navigating this fragmentary and fascinating material.
Do you have other resources you pair with Jeffery? I’d love to hear what we can supplement LSAG with.



